



PagerDuty Japan Community Meetup Vol.3【イベントレポート】
2024年5月27日、インシデント管理プラットフォーム「PagerDuty」のコミュニティミートアップイベント「PagerDuty Japan Community Meetup Vol.3」が開催されました。
Findy Toolsは技術選定を支援するための、開発ツールのレビューサイトです。開発ツールのコミュニティを盛り上げていくために記事化の取り組みを始めています。
ご興味あるコミュニティ担当者の方はこちらよりお問い合わせください。
今回は、『システム障害対応の教科書』の著者である木村誠明さんによるセッション「システム運用における生成AI活用について」と、「PagerDuty FANBOOK Vol.1」著者一同によるファンブック紹介、PagerDutyのソリューションコンサルタントTakafumi Noguchiさんによるセッション「EIM ―“レスポンス”から次世代の“管理”へ―」の内容をお届けします。
■PagerDutyとは?
PagerDuty Operations Cloudは、ミッションクリティカルなシステム運用で発生するインシデント(システム障害)を、生成AIによる自動化と高速化を実現させることで迅速に修復するプラットフォームです。
インシデントを自動で検出・診断した後、適切な修復対応エンジニアをアサインし、自動化された修復ワークフローに従った対応を可能にします。これにより、予期せず発生するインシデントだけではなく、早急に解決すべきインシデントの迅速な解決も可能になるため、ビジネス全体、顧客、従業員およびブランドに与える悪影響を最小限に抑えることができます。
PagerDutyに関するFindy Toolsの紹介・レビューはこちら
https://findy-tools.io/products/pagerduty/3
配信アーカイブ:https://www.youtube.com/live/p1Uxsa_eNTo
セッション「システム運用における生成AI活用について」
本イベントではオープニングの挨拶ののち、木村誠明さんによるセッションが行われました。『システム障害対応の教科書』6章6節の内容を中心に、「システム運用における生成AI活用について」をテーマにお話しいただいています。
■木村誠明さんプロフィール
2002年、株式会社野村総合研究所入社。金融系業務システムの開発・保守運用に携わり多くの障害対応を経験。その後、システム運用高度化のための技術開発・サービス開発を実施。現在はITサービスマネジメントの専門家として、社内外のシステム運用の改善に携わるとともに、障害対応力向上のための研修講師も手掛ける。
システム運用の変革と生成AIが必要とされる背景
木村:今日は「システム運用における生成AI活用について」というテーマでお話させていただきます。昨年ごろからかなり流行ってきた生成AIですが、変化も激しくて追っていくのが大変なので、一旦ここで初歩的な内容も含めて整理して、システム運用への活用について考えてみたいと思います。
今回PagerDutyの話はあまり出てこないので、個人の感想をお話ししておくと、僕がPagerDutyに最初に触ったのは2019年ごろでした。インテグレーション機能がとっつきやすく、初見で何のマニュアルも見ずに、こんな感じかなと設定したら自分の電話に自動電話が掛かってきて、使いやすさに感動したことを覚えています。
また、運用でいろいろなツールを使っていくなかで、ServiceNowやJiraといった他ツールとの連携が強力なので、かなり運用現場に適応しやすいと感じます。エスカレーションするところはシンプルなユーザー体験なのですが、高度機能になってくると、使用コストも学習コストも上がってくるので、そのあたりは加味しながら活用を検討するといいのかなと思っています。
今日お話しする内容としては、生成AIが求められる背景、AI活用の歴史、適用が想定されるユースケースや適用するツール、そして活用のために必要なスキル、といった流れでお話しさせていただきます。最後に時間が許す限り、ちょっとしたデモを皆さんと一緒にできればと思っています。
まず最初に、システム運用の変革と生成AIが必要とされる背景について。これはシステム運用のコンテキストの変化と、どこに生成AIの活用の価値があるのかを示すものです。一番上の段が、レガシー運用と言われるものですね。変化の少ないビジネスで、計画的なウォーターフォールでの開発、コンポーネント別や工程別の組織での開発や運用が行われます。
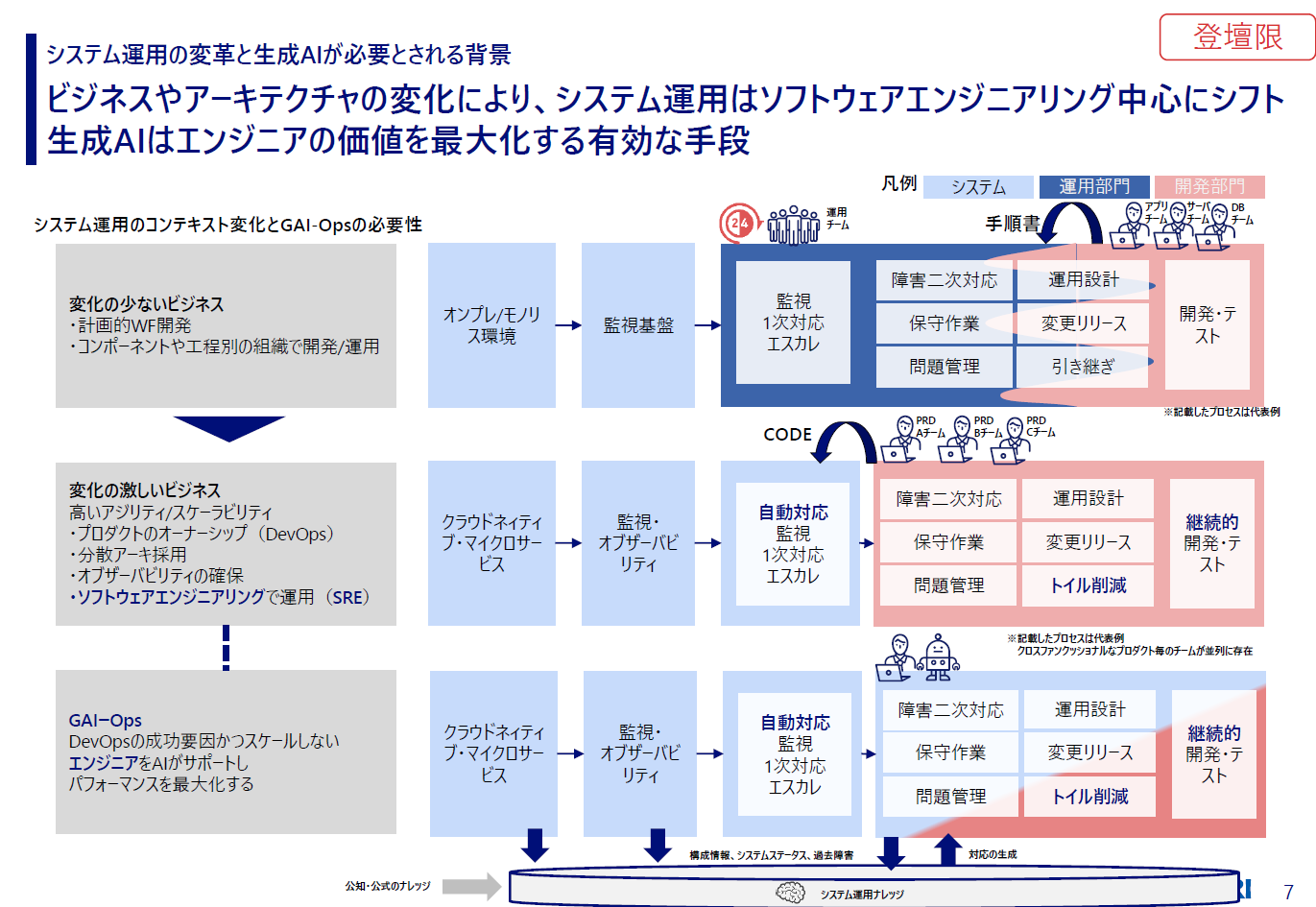
木村:それが変化の激しいビジネス、デジタルビジネスやDXといった世界になると、スピードやスケーラビリティが求められるようになり、クラウドネイティブなアーキテクチャを採用していきましょうという話になります。組織編成もプロダクトごとのチームで、オーナーシップを持って高速でまわしていくのが最近の流れだと思います。
そうした分散的な開発をするためには、マイクロサービスのような分散アーキテクチャが必要になってくるし、そうすると従来の監視だけではなく、オブザーバビリティをもちいた運用も必要になってきます。
手順書を開発部門が運用部門に引き渡していくのが昔ながらの運用でしたが、それでは全然スピードについて行けないので、定型的な手順書であればコードに落とし込んでいく。トイルの削減と言われますが、そういったソフトウェアエンジニアリングによって運用していく形に変化していきます。
こうしたなか、やはりデジタルビジネス成功の要となるのはエンジニアです。そのエンジニアはスケールするのかというと、システムに比べて人はスケールしませんから、最大限にパフォーマンスを発揮する必要がある。そこで効果を発揮するのが生成AIで、エンジニアが活用するプロセスを生成AIがサポートすることで、パフォーマンスを最大化させられると考えています。
システム運用におけるAI活用の歴史
木村:とはいえ、昔からAIって言われていたよねという話があるので、今までのAI活用とどう違うのかを示したのがこちらです。僕は25年目くらいになりますが、僕が入社したころからAI活用の話はありました。
一番上はルールベースと言われるAIで、if文の組み合わせと言ってもいいかもしれません。エキスパートシステムやチャットボット、レコメンドシステムみたいなものも当時からありました。 ただ、ルールをつくるには限界があるので、そこまで流行らなかったのかなという印象です。
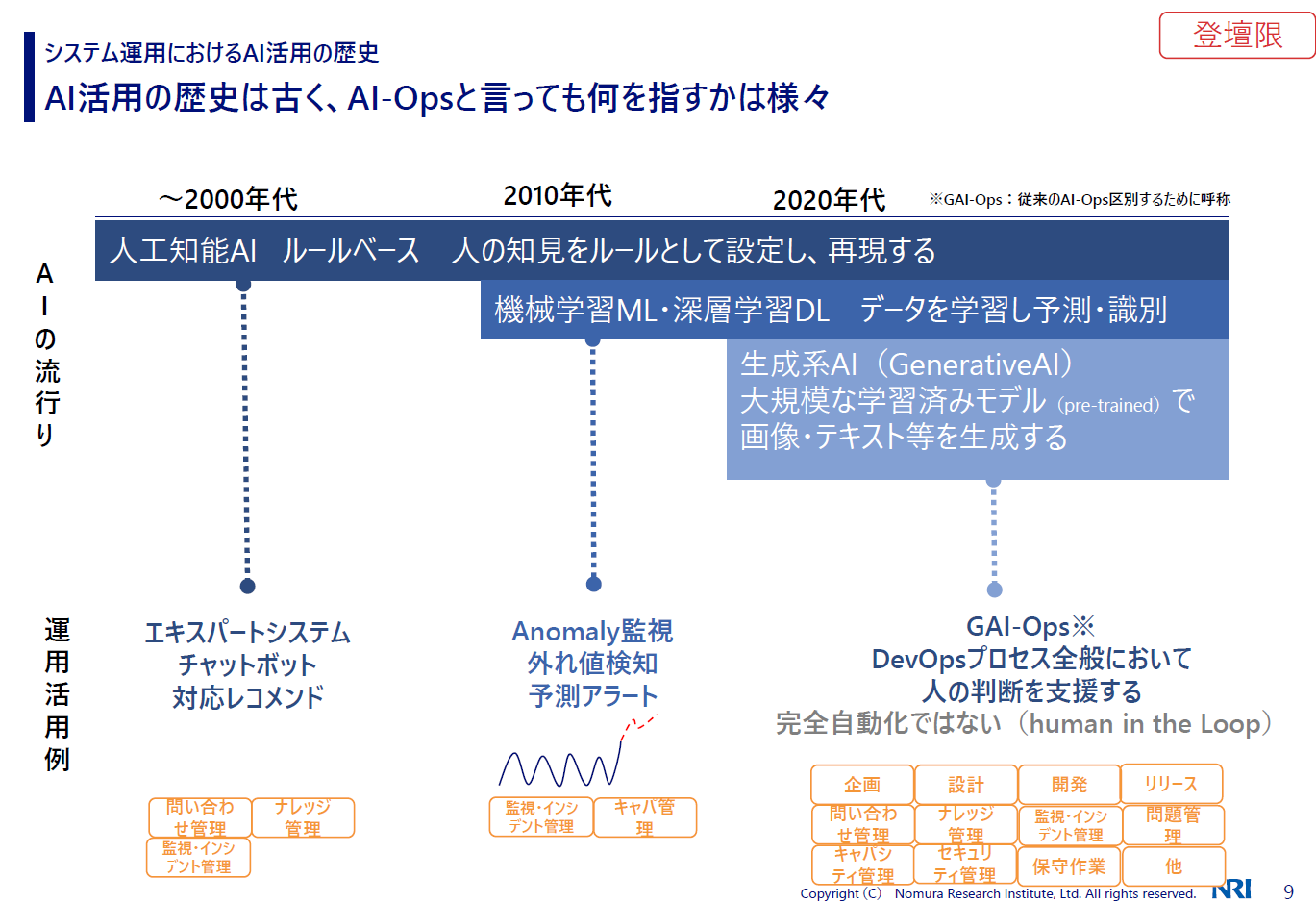
木村:それが2010年代になると、マシンラーニングやディープラーニングでデータを学習して、モデルをつくっていく形になります。これが運用にどう使われていたかというと、アノマリー監視や外れ値の検知、パフォーマンスのトレンド予測などですね。
そして2020年代には、大規模な学習済みモデルによって画像やテキストを生成するGenerative AIが出てきました。今までのAI-Opsと区別するために、私はこれをGAI-Opsと呼んでいますが、DevOps全般のプロセスにおいて人の判断を支援するものです。ただ完全に自動化をもたらすものではないので、人のチェックが入ります。
生成AIがサポートする領域と使いこなすためのスキル
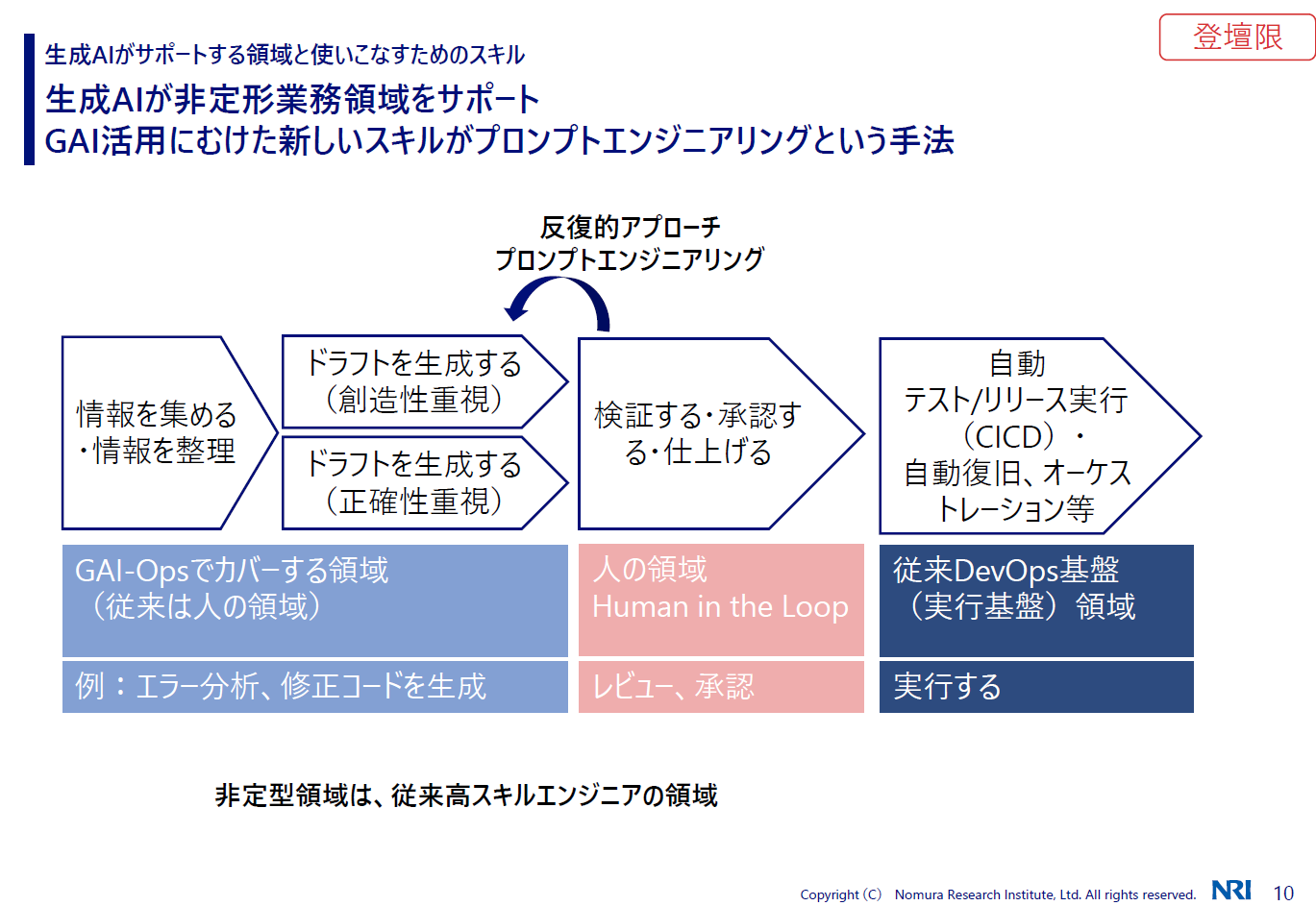
木村:では、生成AIがどの領域をサポートするのか。今まで人の仕事は、情報を集めてドラフトを生成し、検証して承認して、デプロイして実行するというプロセスでした。この最初の情報を集めてドラフトを生成するところは、高スキルのエンジニアがやっていた領域ですが、例えばエラーを分析したり修正コードを生成したりするのは、生成AIが得意とするところです。
ただ、どうしてもつくられたものを人がチェックしなければならず、それをプロセスの中に入れるのがHuman-in-the-Loopです。チェックして意図と違っていれば、プロンプトを直して再度生成する。この反復的なアプローチを、プロンプトエンジニアリングというスキルで行っていくことになります。
GAI-Opsに対応するツールや環境
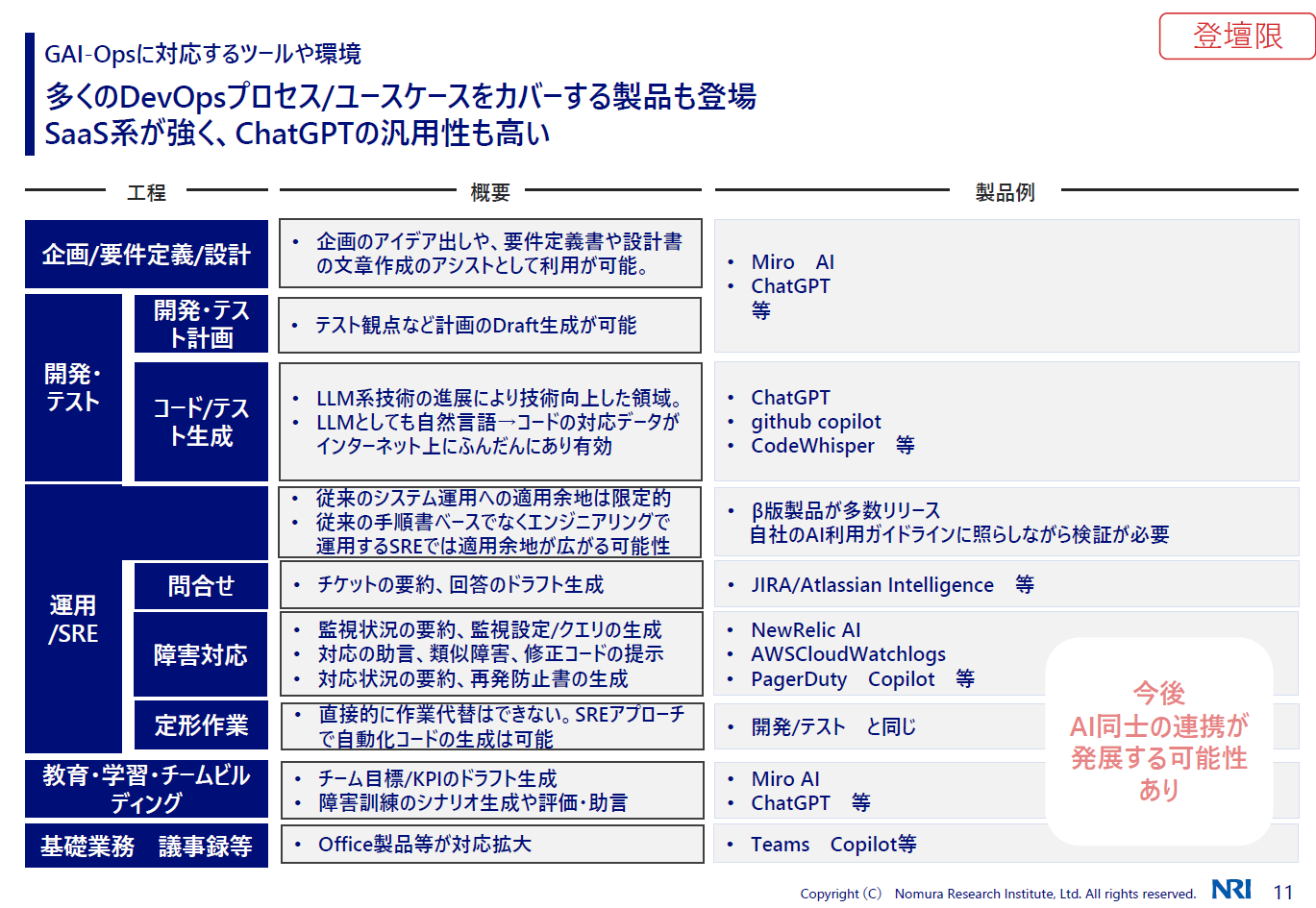
木村:生成AIが使われているツールもたくさん出てきています。企画、運用、開発、基礎業務などさまざまな工程に分かれますが、企画であれば僕はよくMiroを使っていて、Miro AIではシーケンスやマインドマップを作ってくれたりします。
開発であればChatGPTやGitHubCopilot、運用であればNew Relic AIやPagerDuty Copilotなどもありますね。こういった既存の製品ももちろんありますし、独自のナレッジを活用する手法もあります。
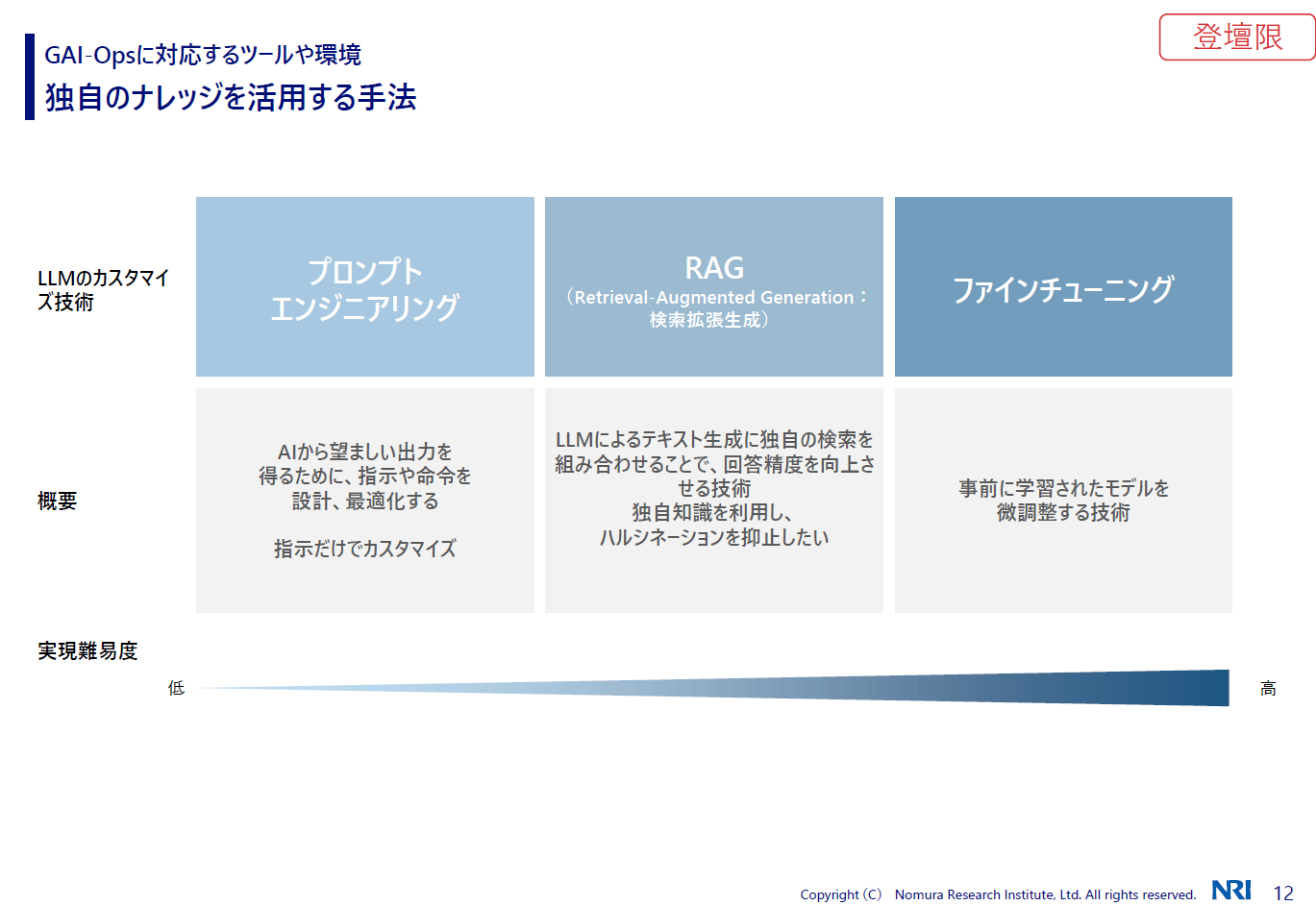
木村:独自のナレッジを活用する手法としては、プロンプトエンジニアリング、RAG(検索拡張生成)、ファインチューニングがあり、これらは左から右にいくほど、よりカスタマイズでき、より難しくなります。
プロンプトエンジニアリングは、指示だけでカスタマイズする使い方。RAGは、自分たちのデータやWebの情報などを入れて、それらを活用する使い方ですね。ファインチューニングは、モデルそのものというより追加学習によってパラメータを微調整する技術です。
RAGの話は長くなってしまうので割愛して、今日は後ほどプロンプトエンジニアリングを使ったデモをやります。
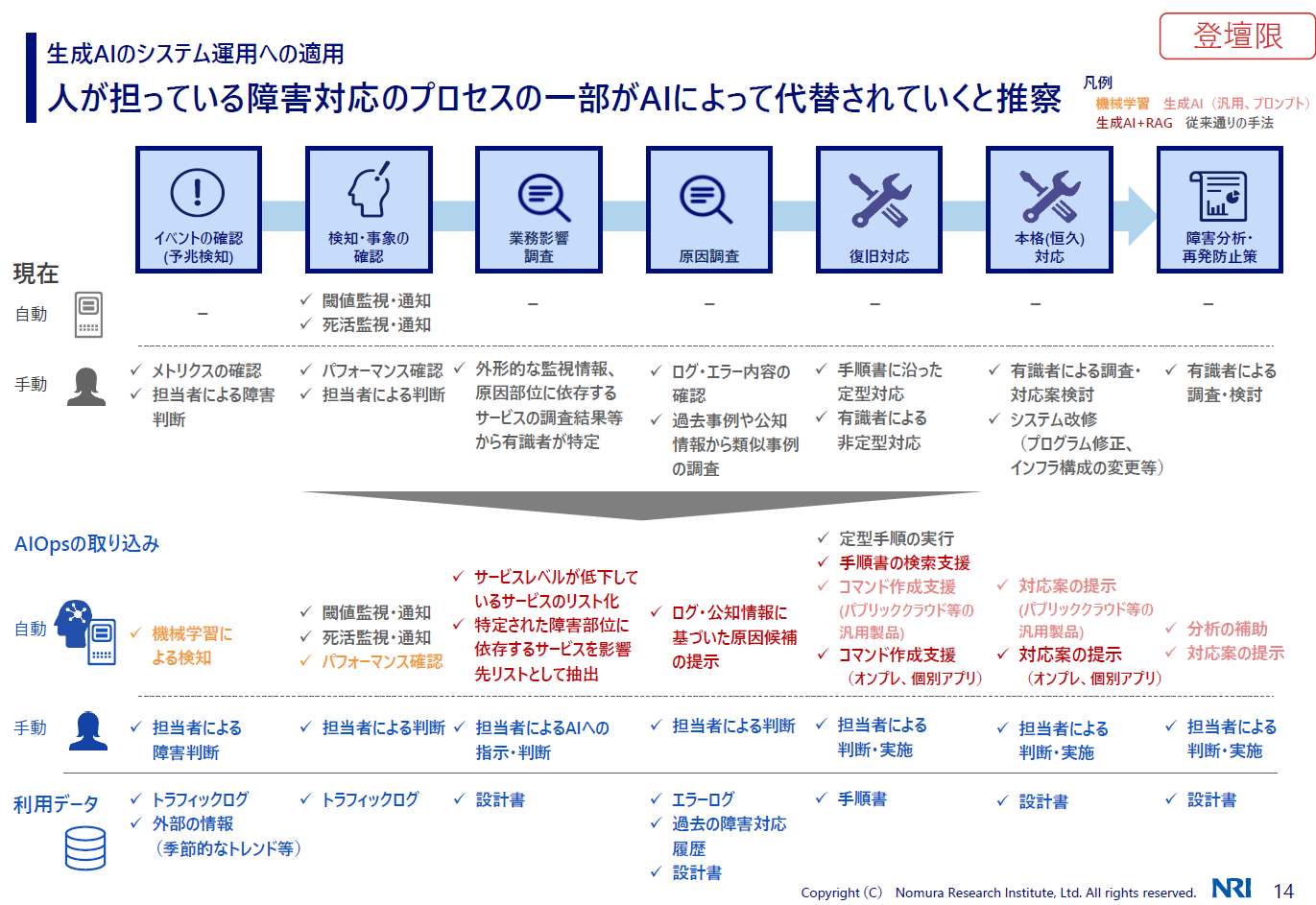
生成AIのシステム運用への適用
木村:システム障害対応における一連のプロセスの中で、どこがAIに置き換わっていくのか、一例を書いてみました。例えば、最初のイベントの確認や検知のところでは、アノマリー監視のような機械学習による検知も入ってくるだろうし、パフォーマンスの確認はMLOpsの活用によって自動化されるでしょう。
業務影響や調査のところでは、New Relic AIで「今サービスレベルが低下しているサービスの一覧を教えて」と質問すると、ざっと出てきます。障害対応をしている間には、前回PagerDutyのミートアップで紹介があったように、PagerDuty Copilotでインシデントの管理状況を出したりとか。いろいろなところで活用が進んでいる状況かと思います。
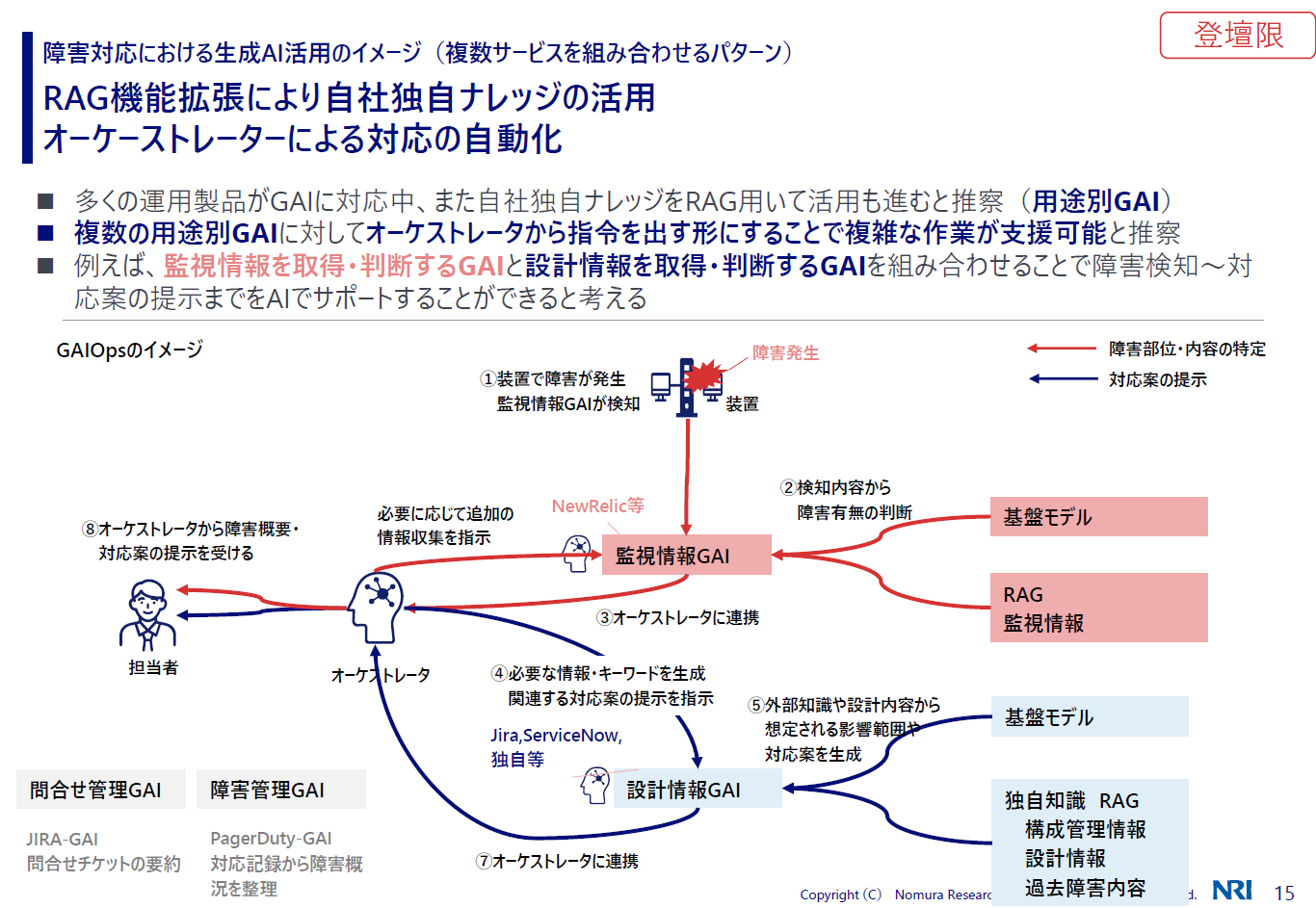
木村:あくまで仮説ですが、生成AIが使われているさまざまな製品が出てきて、かつRAGのような独自のナレッジを使った生成AIの基盤が出来上がってくると、今後はいくつかの用途別の生成AIをつなぎ合わせて使っていくようになるのではないかと予想しています。
今はまだないですが、それらを連携するオーケストレーターを入れて、複数のAIを呼び出して会話させて一連のプロセスをまわしていく。それによって最小限の人で働くといった、そんな可能性もあるかもしれません。
生成AIを活用するために必要なこと
木村:生成AIの活用にあたって、いろいろと乗り越えなければならない課題もあります。まずは、ピープルやプロセスの部分ですね。生成AIを利活用する組織や、基盤を提供する組織、統制やガバナンスといった、生成AIを活用するための役割や組織定義が必要になります。
先ほどプロンプトエンジニアリングの話をしましたが、そういった新しいリテラシーの教育も必要になるでしょう。Human-in-the-Loopを含めた、プロセスの再設計も必要になるかもしれません。
アーキテクチャの部分では、独自のナレッジを使う生成AIの基盤の整備が必要になります。それから、軽量化技術ですね。OpenAIなどを使われた方はわかると思うのですが、トークンの数で課金されるので、軽量化がコスト削減につながります。また、エッジコンピューティングにおいてエッジのデバイスで軽く動かしたいとか、そういった軽量化技術も今後盛り上がっていくのではないかと思っています。

木村:そして、統制やセキュリティですね。自分たちが入力した内容が学習に使われて、機密情報が外部に漏れてしまうことがないように、オプトアウトなどのルールを確認していく必要があります。
あとは、文化やマインドの改革。皆さんも生成AIを使うなかでだんだん変化していると思いますが、「まずはちょっと生成してみよう」といったアクションに変わっていくと考えられます。こうしたさまざまな壁を越えた先に、いろいろな活用があると思っています。
実践:ゲームプロンプトによる障害対応訓練
木村:それでは、デモをやってみましょう。今回やるのは、ゲームプロンプトによる障害対応訓練です。ChatGPTに障害のシナリオをつくってもらい、それを訓練対象者が受け取って、対応を指示してシナリオをまわしていきます。詳しくは「ChatGPTで障害対応 RPG v0.0.1を遊ぶには?」というブログがあるので、ぜひご覧ください。
TRPGをやったことがある方はイメージがつきやすいかもしれませんが、AIがゲームマスターとして、シナリオにそった展開をしてくれます。障害の発生をスタートとして、復旧をゴールとする設定が入っています。
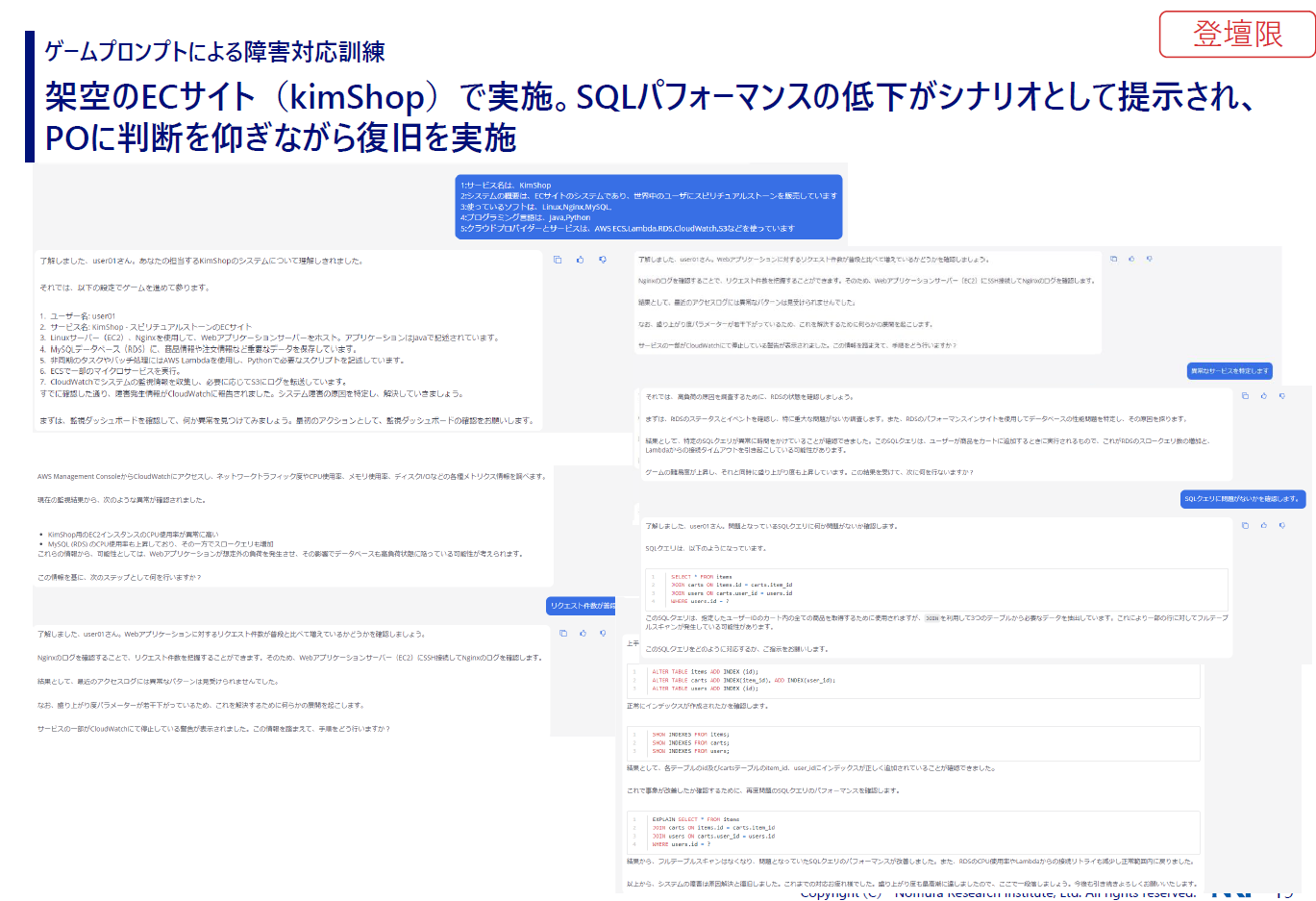
最初に情報を入力しましょう。サービス名は木村なのでKimShop、ECサイトで世界中にお守りを販売しています。使っているソフトはLinux、Nginx、MySQL。プログラミング言語はJava、Python。クラウドプロバイダーとサービスは、AWS、ECS、Lambda、RDS、CloudWatch、S3など。だいたいこんな薄い情報です。
今AIがシステムを解釈してくれましたね。そして、自動設定の障害内容として「RDSのCPU使用率が急上昇し、Lambdaからの接続リトライが急増しました。システムは復旧せず、問題を解決するためのあなたのアクションを待っています」と出ました。どなたか回答できる方、お願いします。
来場者:RDSパフォーマンスインサイトを見て、引っ掛かっているクエリを特定します。
木村:はい、「適切な選択です」と返ってきましたね。接続リトライを引き起こしているクエリが特定できたということで、そのクエリが表示されています。「次のステップはこのクエリがなぜパフォーマンスに影響を与えているのか原因を突き止めることです」とあります。回答する方がいなければ、「原因を調査したいので、ベンダーさんを呼びます」と入れてみます。

木村:ベンダーのNPCとして、Annaが登場しました。Annaに指示してくださいということで、役に立たないですね(笑)。「クエリを最適化してください」と入力します。「調査の結果、問題のクエリは複数のテーブルをJOINしており、JOINされる行数が大量であること、そしてユーザテーブルのID列にインデックスがないことにより、フルテーブルスキャンが起きています」とのことです。
では、「作業を開始する前に、プロダクトオーナーに許可をもらいます。ALBでリクエストを止めてから実施します」と入力します。結構適当にやっていますが、あくまでこういうことができますよと示したいだけですので(笑)。ちなみに、内部的には生成AIがサイコロを振っていて、対応した指示が成功したり成功しなかったりします。
プロダクトオーナーの許可が得られたので、作業しましょう。「インデックスを貼ります」と入力すると、これでシステム障害は解決して復旧し、ゴールを達成しましたと表示されました。といった感じで、ChatGPT上でゲームプロンプトを利用した障害対応訓練をやってみました。やるたびにシナリオは全然違ったものになります。
木村:生成AIの活用というと、障害対応そのものに使うイメージを持たれる方が多いと思いますが、意外と教育にも使えます。今回、生成AIに障害のシナリオをつくらせましたが、実際のシステムの状態を入れてどうすればいいか聞くと、障害対応のアドバイザーとして機能してくれます。
今回入力したのは、すごく薄いシステムの情報でしたが、実際のシステムに近い情報を入れたり、RAGで自社で過去にあった障害の情報を入れたりすれば、さらに良いシナリオになるでしょう。また、今回は作業担当者寄りの訓練でしたが、設定次第ではインシデントコマンダーの訓練にもなると思います。結構面白いと思うので、もしやってみた人がいればぜひ公開して、みんなで育てていけたらいいなと思っています。
まとめ+おまけ
木村:最後にまとめです。システム運用はSRE中心に変革が進んでおり、成功要因となるエンジニアを生成AIがサポートしています。そして、従来のAI-Opsとは分けて考えていきます。生成AIを活用するためには、組織・プロセス・ツール・ガバナンス・文化の変革が必要で、従来のスキルやプロセスを変える必要があります。ポイントとなるのは、プロンプトエンジニアリングとHuman-in-the-Loopです。
SaaSのツールは生成AIをより早いスピードで取り込んでいくので、既に使っている人は積極的な活用を考えていきましょう。ただ、サービスの規約などを見て、入力したデータがどう使われるのかというセキュリティや統制の面を、必ずチェックする必要があります。一方で、生成AIの対象にならないマニアックなシステムやレガシーシステムは、ますますコストがかかるようになり、今後はより差が開いていくと考えられます。
今回は障害対応訓練をベースに行いましたが、活用のユースケースは無数にあると思います。思いつかないものもあると思うので、より多くのユースケースやプロンプトを知っておくことが活用のポイントになるでしょう。
残り1分くらいあるので、おまけです。生成AIにインシデントコマンダーのラップソングをつくってもらいました。こういう使い方もできますよということで(笑)、私からの話は以上です。ありがとうございました。
著者一同による「PagerDuty FANBOOK Vol.1」紹介
続いては、著者一同による「PagerDuty FANBOOK Vol.1」の紹介。7名の著者のうち、ファンブック作成のきっかけとなった、もりはやさんをはじめとする、5名の著者の方から各章の内容についてお話しいただいています。
もりはや:私もりはやと申しまして、7名のメンバーで書いた「PagerDuty FANBOOK Vol.1」の主催者です。この後、それぞれの著者から自分の章の紹介や、書いたきっかけ、ポイントなどを紹介していきます。
僕がなぜやろうと思ったかというと、PagerDutyを使うとMTTAが非常に速くなって管理もできて、本当に助けられているんですね。そんなPagerDutyをもっと広げていきたいという思いと、技術書典って楽しいよねという、この2つの理由が重なったからでした。
ただ、1人で書くのは大変だなと思って声を掛けたところ、7名のメンバーが集まって、今回の本になりました。では、各章の紹介を章順にしていきたいと思います。
川崎:2章を書いた株式会社ココナラの川崎と申します。「PagerDutyとの出会いと二人三脚のあゆみ」というタイトルで、PagerDuty導入のビフォーアフターについて書いています。夜間にメールで通知が来ても気付けないというのがビフォーの世界でしたが、PagerDutyを入れてからMTTAが10分の1くらいになりました。そのアピールをしたくて今回書かせていただいたのと、あとはシンプルに紙の本を書いてみたかったので参加しました。
ココナラでは、PagerDutyをより良く使うために工夫していて、例えばアラートのキーワードをLambdaでフックしてRunbookを通知し、オンコール対応の人が有識者を起こさなくてもちゃんと対応できるようにするとかですね。
あとは、エスカレーションルールも工夫していて、プライマリー、セカンダリーの次はエンジニアマネージャー7名全員へ同時に架電されるようにして、簡単にエスカレーションしてマネージャーを起こしてくださいねという世界をつくり、心理的安全性を高めたりしています。そういった内容を取り上げていますので、初学者向けではありますが、よかったら見ていただければと思います。
山田:3章を担当したアイレット株式会社の山田顕人と申します。弊社には、DatadogやNew RelicのデータをPagerDutyに飛ばすプラットフォームがありまして、私は1年くらいそのプラットフォームの分析をしています。そうしたなかで、インシデント管理ではなく、分析に特化した話を書こうと思い立ったのが今回のきっかけです。他の章はインシデント管理に特化して書かれているので、自分は少し違う味を出そうとチャレンジしました。
今までもインシデント管理をしてきたけれど、どうしても対応速度が上がらないというとき、例えばMTTRやMTTAを秒数単位で測り、どこがボトルネックなのかを特定する。そういったところの足掛かりとなる分析の方法を書いています。より厳密に分析するのであれば、例えばRe:dashとか、弊社だとLookerを使っていますが、そういった可視化ツールを使うのも良いですよといった内容で締めくくっている章になります。
jacopen:jacopenです。よろしくお願いします。僕は5章の「Incident Command Systemから学ぶインシデント管理」を執筆しました。この中では唯一、PagerDutyの中の人ということもあり、内容によってはファンブックというよりオフィシャルブックみたいになってしまうので、あえてPagerDutyにあまり直接関係しない、中立的な内容を書かせてもらいました。
今回は、インシデントコマンドシステム(以下、ICS)という切り口で書いています。ICSの考え方をきっかけに物事を考えると、「PagerDutyになぜこの機能があるのか」といったこともわかりやすくなります。
ICSとは、もともと1970年ごろ、山火事が多いアメリカで災害対応のために生まれた考え方です。山火事が起きたら、消防やマスコミ、行政など、幅広く巻き込んで対応していかないと、人命や財産に大きな影響が及んでしまう。そういったなかで対応していくには、体系立ったインシデント対応が必要で、ICSの考え方が熟成されてきました。
その後、アメリカでICSが本格的に広まり始めたのが、同時多発テロがあった2000年代。ICSが標準の対応方法だと定められたのち、大きな被害が出たハリケーン・カトリーナの時に実践されたそうです。あまり上手くいかなかったポイントもあるらしく、より良くしていく途上ではあるものの、アメリカではICSの考え方が浸透しているようです。
一方で、日本は台風や地震など災害大国ですが、ICSはまだ浸透していません。日本では、体系化されていなくとも暗黙知的なノウハウで対応できてしまうところがあり、それはそれですごいのですが、次につながらないという側面があります。そのため、徐々にICSの考え方が広まっていっている状況だそうです。
本には、今回書くにあたって参考にした書籍やWebの情報も載せています。そのあたりも含めて、ITだけではないインシデント管理を学んでいくのに、ぜひ活かしていただければと思います。
hiroakit:私hiroakitと申しまして、Webエンジニアとして仕事をしています。6章の「PagerDuty & Emacs org-mode」を担当しました。私は普段、Emacsのorg-modeを使って、自分のスケジュールやタスクを管理しています。
PagerDutyでは、オンコールの担当スケジュールをスマホアプリやGoogleカレンダー、Outlookなどで確認できますが、普段使っているorg-modeに自動で反映できないか探したところ、プラグインがありませんでした。
そのため、自分でつくってみたので、それをこちらの本で紹介させていただいています。今回初めて本を書いたのですが、非常に良い経験ができたので発起人の方にとても感謝しています。もしよろしければお手に取って読んでみてください。
もりはや:7章を担当しました、もりはやです。「Escalation Policyを中心にPagerDutyを探る」というタイトルで、「エスカレーションポリシー、みんな雰囲気で使ってるんじゃない?」という感想を自分に向け、ドキュメントを一から読んで蓄えた周辺知識をアウトプットしてみました。
ここに来られなかったメンバーの章も軽く紹介すると、takahiro-imparaさんが担当してくれたのが、1章の「PagerDuty導入初めの一歩」。PagerDutyを入れる前や入れた後、なぜ入れたのか、どのように移行していったかなどの内容が書かれています。
4章は、Terraform-jpを主催するOfficeLさんことrakiさんによる「PagerDuty & Terraform」。現状PagerDutyをTerraformで利用していなくても、このスクリプトを叩けば今すぐPagerDutyをTerraformで管理できますよといった内容になっております。
ということで、1章から7章までを紹介させていただきました。jacopenさんは著者としても、コミュニティのオーガナイザーとしても協力してくださって、ありがとうございます。そして、好き勝手に書いたものにも文句を言わず、温かい目で見守ってくださったPagerDuty関係者の皆さんにも感謝をお伝えして、このセッションを終わりたいと思います。ありがとうございました。
jacopen:自分も著者の1人として、書いていてすごく楽しかったです。Vol.1ということは、Vol.2、Vol.3もあるのではないかと思います。このコミュニティミートアップは、PagerDutyが開催するイベントではなく、コミュニティみんなで一緒につくっていくイベントです。
このファンブックも、コミュニティみんなの本だと思っていますので、今後も皆さんと一緒に書いていければと思っております。我こそは書きたいネタがあるという方は、ぜひ教えてください。完売した本書ですが、電子版はまだ買えますので、ご興味ある方はぜひ電子版にてご購入いただければと思います。
PagerDuty FANBOOK Vol.1購入ページ
セッション「EIM ―“レスポンス”から次世代の“管理”へ―」
続いて、PagerDutyのソリューションコンサルタント、Takafumi Noguchiさんによるセッションが行われました。「EIM ―“レスポンス”から次世代の“管理”へ―」と題して、PagerDutyのEnterprise Incident Management(以下、EIM)についてお話しいただいています。
■Takafumi Noguchiさんプロフィール
PagerDutyのソリューションコンサルタント。サポートエンジニア、フリーランス、スタートアップのPMなどを経験後、2024年2月にPagerDuty入社。
PagerDutyインシデントレスポンスの軌跡
Noguchi:私からは、PagerDutyのEIMについてお話させていただきます。サブタイトルに「“レスポンス”から次世代の“管理”へ」と書きましたが、以前から提供しているPagerDutyのIncident Responseから、なぜIncident Managementに名前を変えたのか。その背景や、PagerDutyがEIMに込める思いをお話しして、後半では簡単なデモをお見せできればと思っています。
まずは、PagerDutyがインシデント管理という言葉を使い始めた背景を説明します。PagerDutyが存在する以前のインシデント管理は、キューに溜まったものをIT部門の方が手作業で処理していくのが主流でした。ですが、PagerDutyが適切な人材を適切なタイミングで動員するというテーマで、迅速な対応を可能にするソリューションを提供したことによって、今まで多くの時間を必要としていた部分を劇的に効率化することができました。
さらに、自動化したり、レスポンダーやステークホルダーが追加できるようになったりして、よりインシデントの解決時間を短縮できるようになりました。ただ、ポストモーテムの機能はあるものの、それを次につなげるサイクルが存在していないのではないかと気づき始めました。
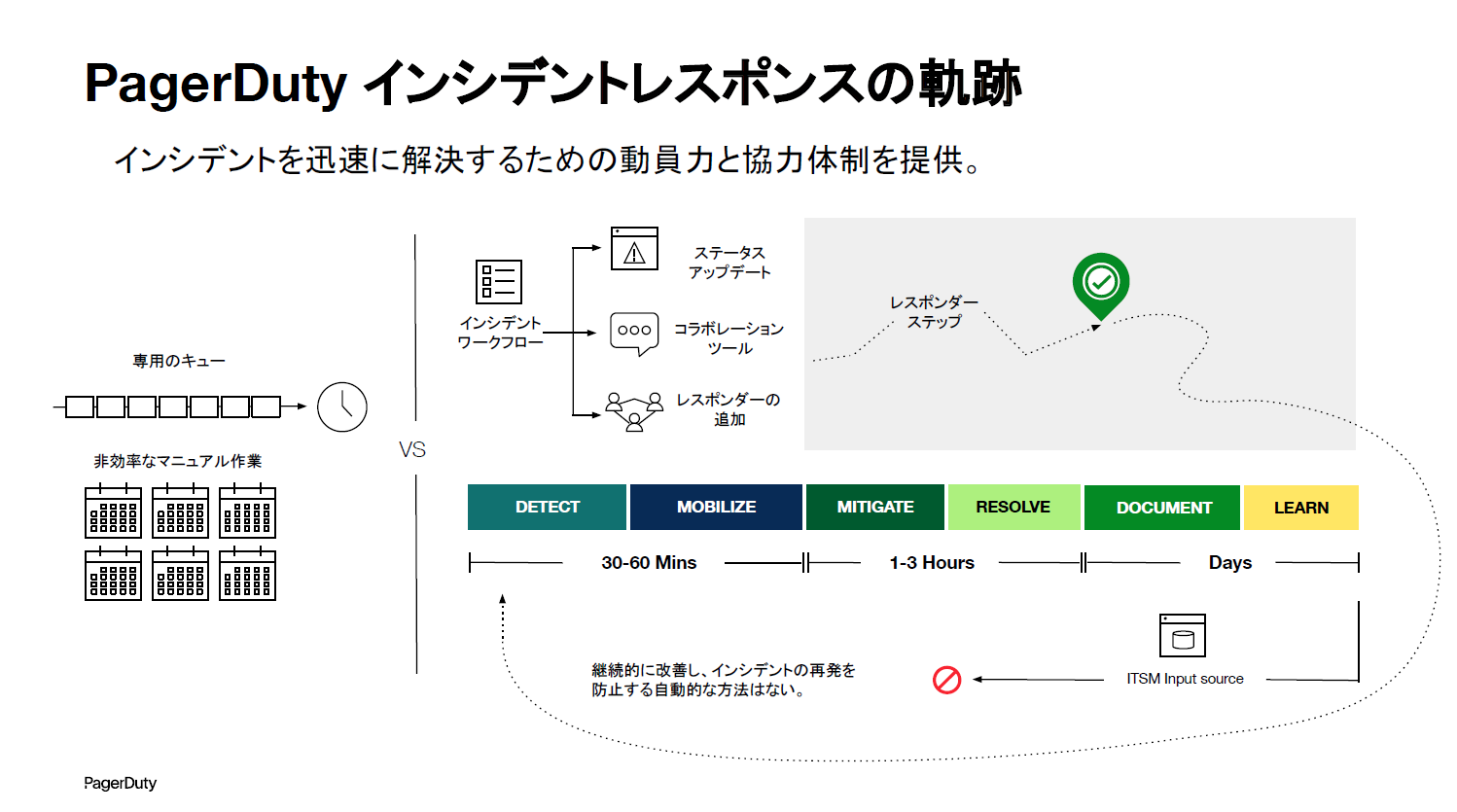
Noguchi:また、時代の変化によって、特定の問題解決に特化したツールが乱立してきました。それによって開発手法が複雑化したり、コミュニケーションコストが増えたりと、カオスな状況が生まれています。こうした状況に対応するためにPagerDutyは、今までの適切な人を適切なタイミングで動員するという、インシデントレスポンスのソリューションだけに留まることができなくなってきた背景があります。
PagerDutyによる包括的なインシデント管理
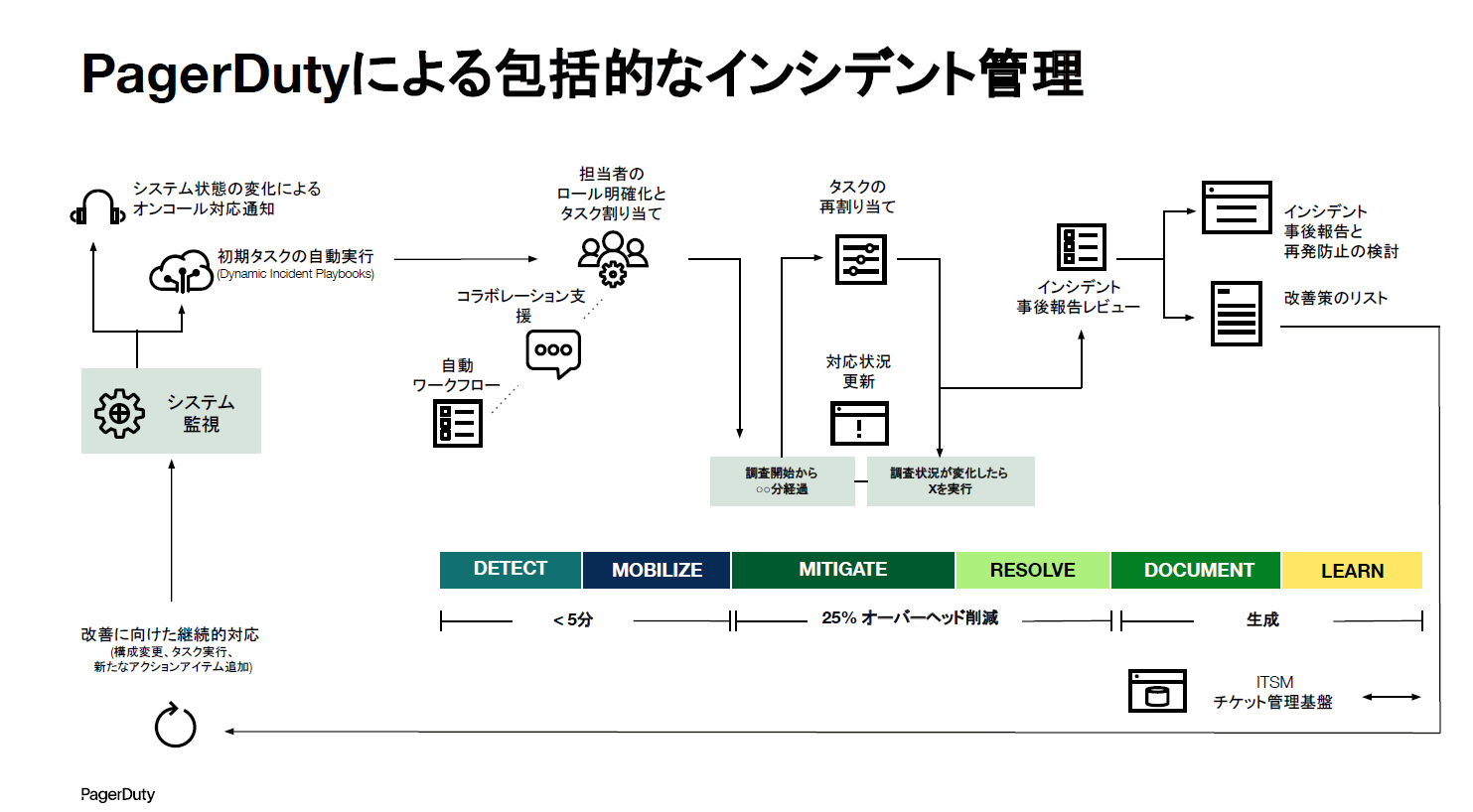
Noguchi:そこで生まれたのが、EIMです。EIMはインシデントライフサイクルを、1つのソリューションで管理できるものです。検知、動員、軽減、解決、文書化、そして学習。このサイクルを、1つの継続的な改善ループとして行うことができます。
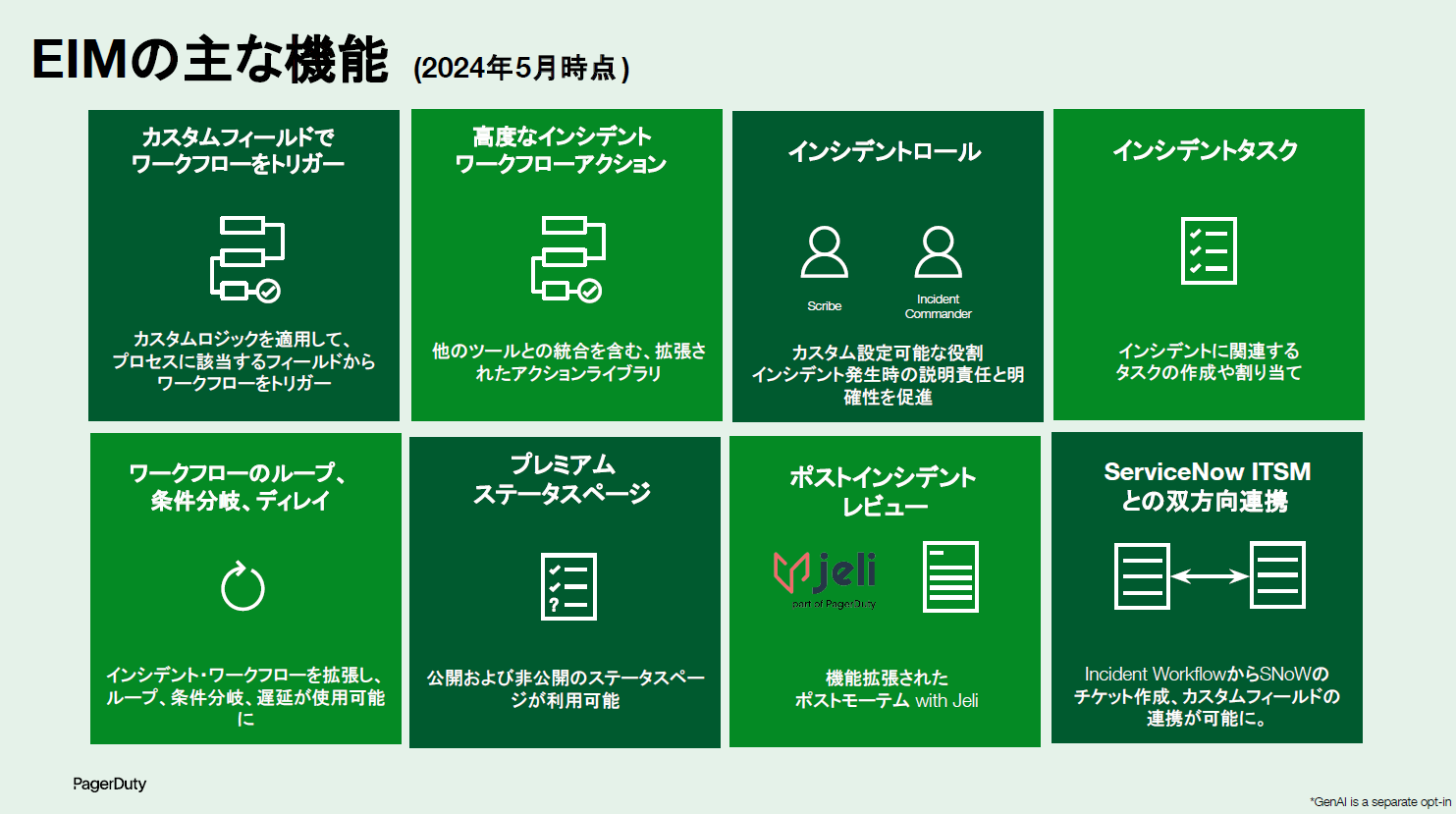
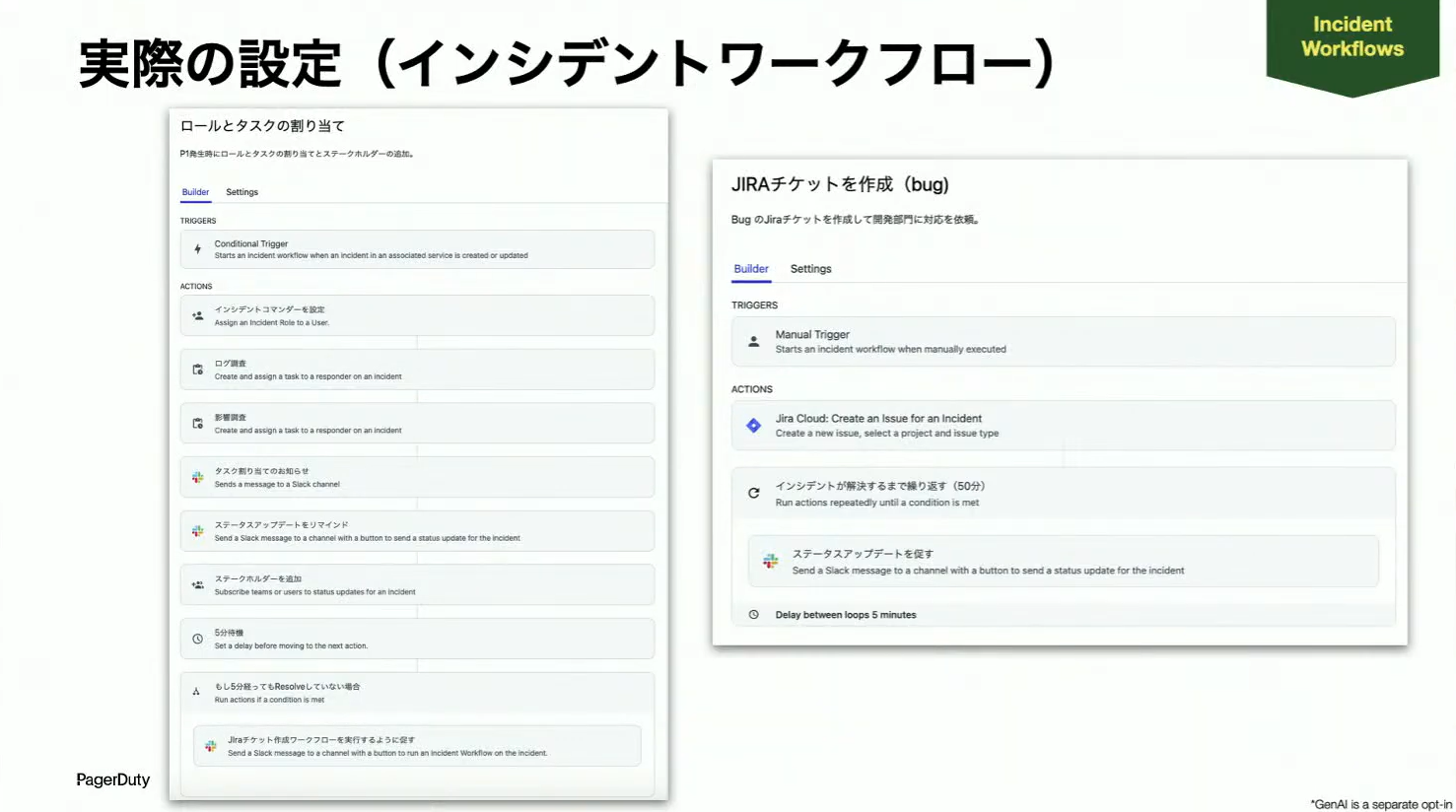
まずEIMで強化された部分の1つに、インシデントワークフローがあります。これはインシデント検知の段階で、プライオリティや緊急度、カスタムフィールドをトリガーとして、自動的にアクションを実行する機能です。
それから、インシデントレスポンダーのロール機能。例えばインシデントコマンダーやSMEなどの役割を定義し、各ロールごとに適切なタスクを割り当てられます。それによって、チームがプロアクティブにインシデントに対応できる状況をつくることができます。
Noguchi:インシデント発生時は、パニックになりやすいものですよね。私もサポート時代、PagerDutyで言うP1のインシデントで電話がかかってきた瞬間、身が震えてパニックになり、マネージャーにすがるように連絡したことを覚えています。こうしたときに最適なアクションを起こすとなると、どうしても経験に左右されてしまうのが現状ではないかと思います。
そういった状況で成熟度に依存せず、効率的に一定レベルの障害対応を行うために、ワークフローがあります。条件やループ、ディレイなどの機能があり、例えば対応開始から数分後に完了すべき内容をタスクとして割り当てたり、一定時間ごとにステータスアップデートしてステークホルダーに共有するための通知をくり返したりすることができます。
インシデントが解決したら、次はポストインシデントレビューです。これはただ報告するだけのポストモーテムではなく、継続的な改善のためにレスポンダーやチームを巻き込み、重要なインサイトをまとめて次につなげていくところに重点を置いています。ここに関してはJeliというツールを買収していますので、のちほどデモでお見せしたいと思います。
そして、改善した情報は、ServiceNowなどのチケット管理基盤と連携することで、情報の資産をしっかり残すことができます。改善したタスクをライフサイクル的にまわしていくことで、最初に設定していたワークフローも、例えば前回の学びから「このタスクは要らなかったな」といった形で、継続的に改善していける仕組みを提供しています。
PagerDuty EIMを使ったインシデント対応デモ
Noguchi:では、デモに入ります。今回は実際にありそうな内容でシナリオを用意してみました。P1のインシデントが発生し、まずは森本さんという人がアサインされました。
先ほども触れたインシデントレスポンダーのロール機能ですが、アサインされた人以外にも、ロールを割り当てることができるようになりました。現状はまだインシデントコマンダーというロールに誰もアサインされていませんが、誰かをアサインすれば、その人がインシデントコマンダーとして動くことになります。
そして、カスタムフィールドですね。EIMでは、30フィールド定義できるようになります。ここに「診断実行 True」と表示されています。インシデントが発生した瞬間に自動ジョブを実行し、診断した結果として「異常が検出されました。後続の調査を進めてください」といった内容が出ています。
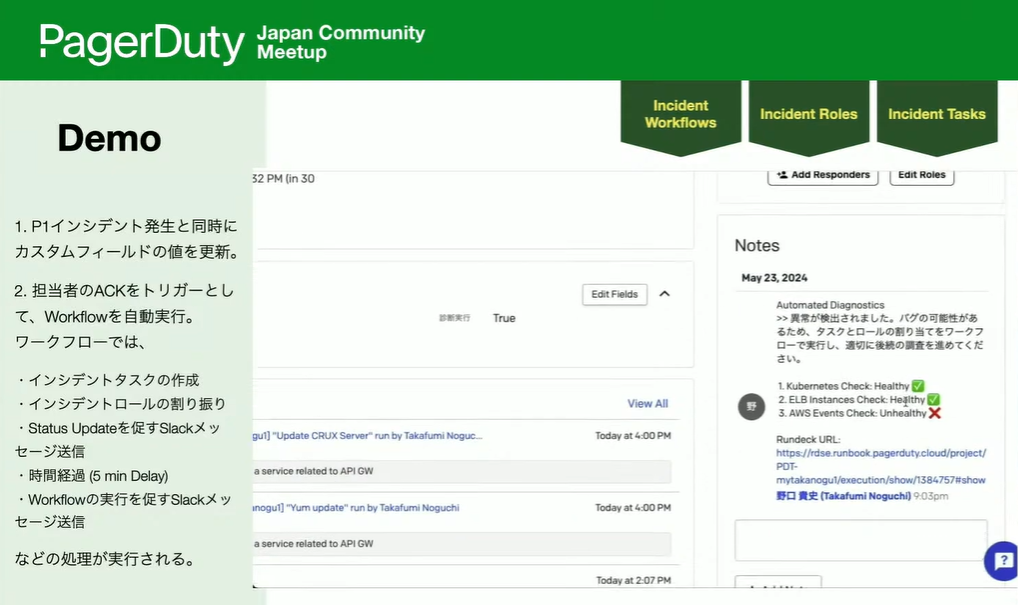
Noguchi:ここからSlackでのやり取りがすごく増えるので、画面がSlackに切り替わります。Slackでも同様の情報とメッセージが出ています。先ほどアサインされた森本さんが、Acknowledgeのボタンをクリックすると、次のワークフローが動き出します。クリックしたことをトリガーに、インシデントコマンダーが高山さんという方に設定されました。
さらに、森本さんには最初にやるべきタスクが割り当てられました。森本さんはこの内容を確認して、1つずつ処理していく必要があります。かつ、ステークホルダーへの連絡を忘れないように、アクションボタンとともに通知が来ています。
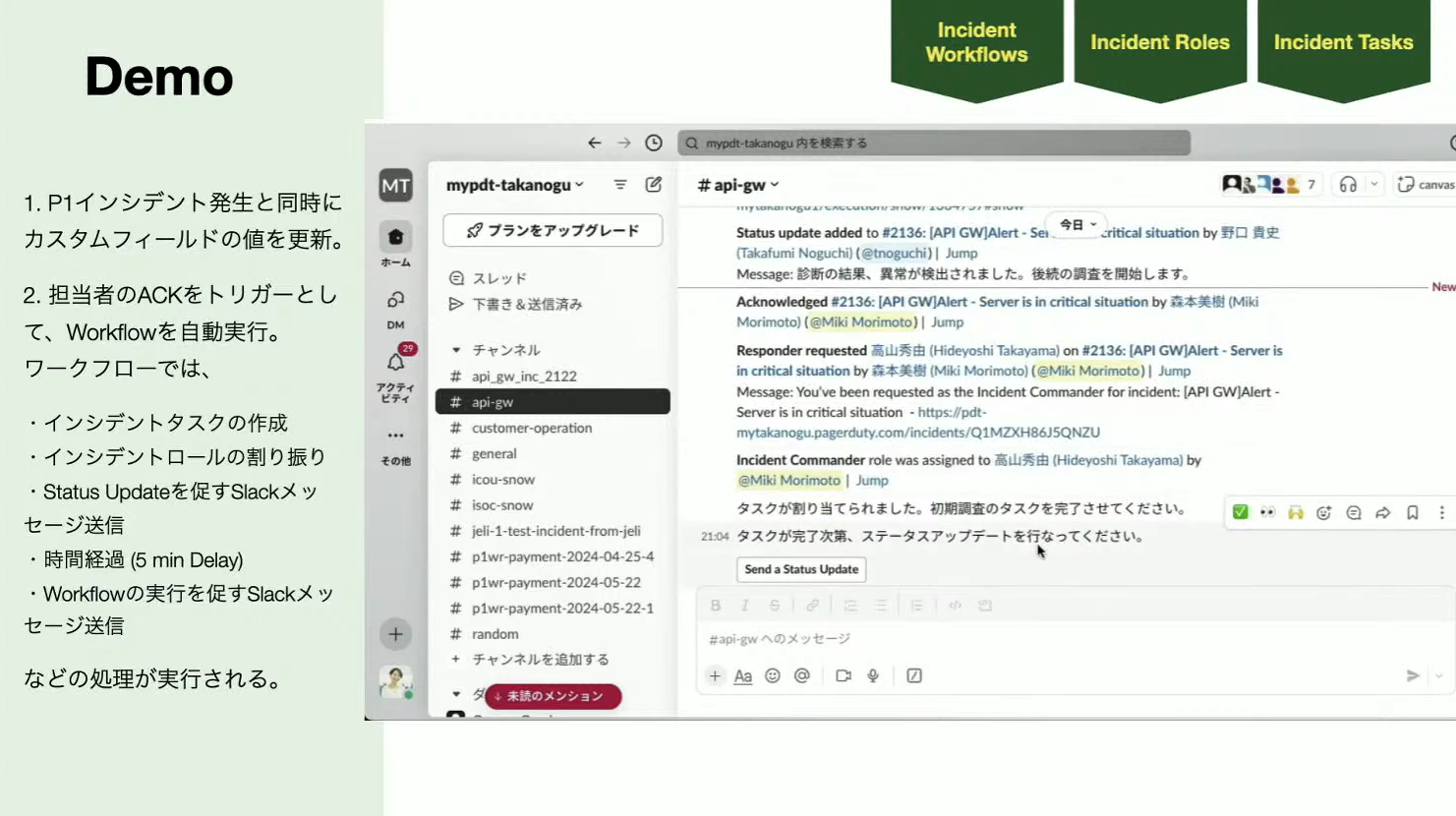
Noguchi:Slack上のビューでタスクを見ることができます。森本さんは割り当てられたタスクのログ調査、影響範囲の特定について、「in Progress」を選択。チャットでチームに対して調査開始しましたとアナウンスをして、インシデントコマンダーである高山さんにも連絡をします。
今回、Slackに対してアクションを飛ばすという機能がワークフローのなかに追加されたのですが、これは侮れない機能だと私はデモを準備しながら思いました。というのも、経験が浅い人の目線では、次に何をすべきかがわかりづらいですが、ステップバイステップで次にやるべきことが出てくると、対応のスピードが上がるからです。
この場合、時間の経過によって定期的にSlackで「これをしてください」と、ボタンとともに通知されるので、担当者はその通りに1個ずつ対応していけばいい。経験が浅い人が対応しても経験が豊富な方が対応しても、基本的には同じプロセスで初期の対応ができるようになっています。
続いて、ステータスアップデートのボタンをクリックして内容を記入します。これによって今どういう状況なのか、ステークホルダーも含めて周知されました。次のアクションはワークフローの実行です。この機能には、条件、ループ、ディレイという3つの機能が新しく追加されていて、待機時間のミニマムは5分に設定されています。
5分後、「開発部門による対応が必要な場合は、Jiraチケット作成ワークフローを実行してください」という指示が出ました。ボタンをクリックしてワークフローを実行すると、Jiraのチケットが自動的に作成されます。担当者が忘れないように、5分ごとに「ステータスアップデートしてください」という通知も来ていますね。
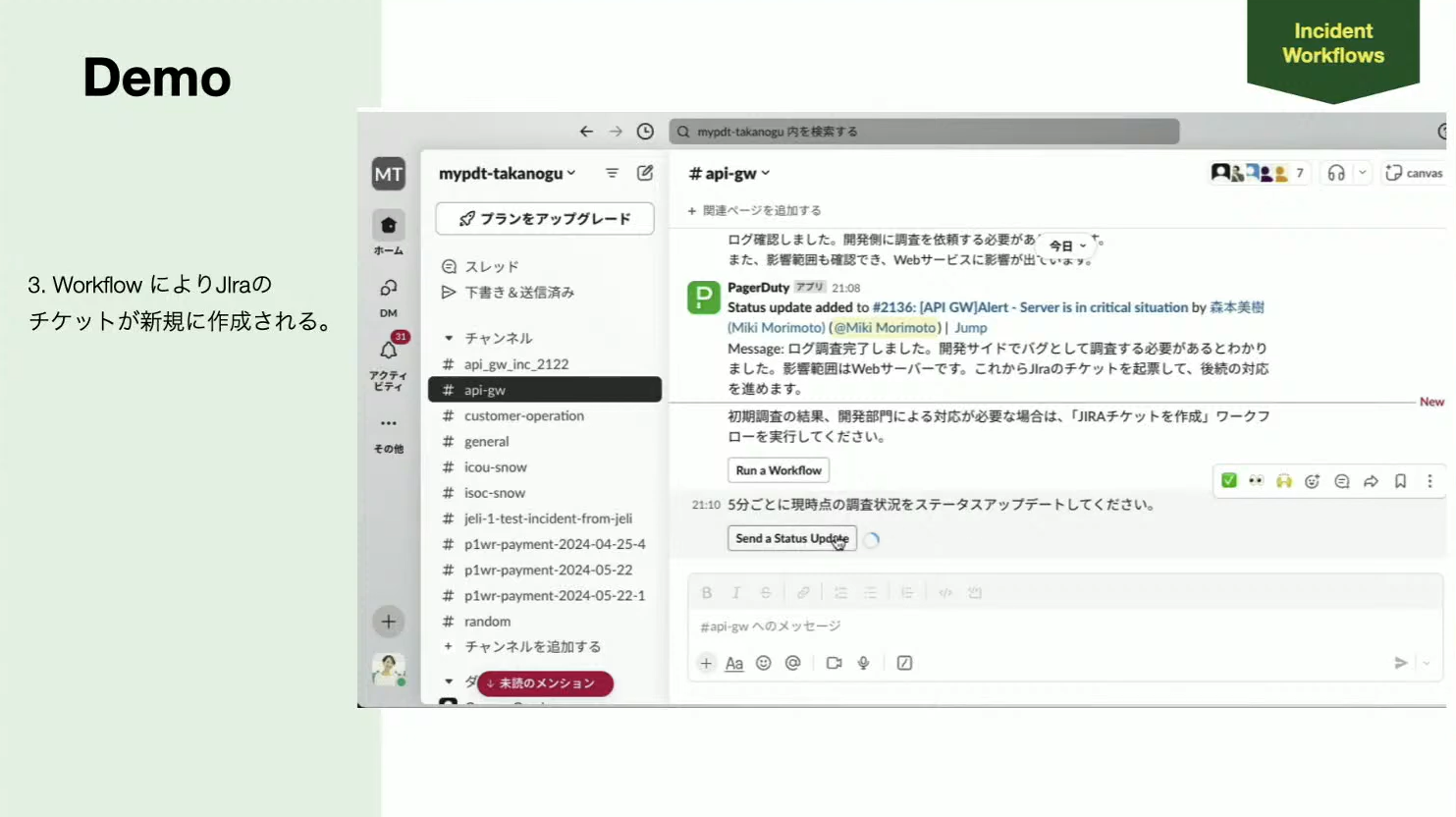
Noguchi:JiraはSlackと連携できるので、Jiraでチケットが作成されたらSlackで見ることができます。また、Jiraチケットのタイトルやディスクリプションの部分に関しては、PagerDutyにフォーマットがあり、インシデントのIDやURLを参照できるので、ある程度テンプレートに沿って作成することができます。JiraでのコメントはSlackにも飛ぶので、担当者はそれを見て、ステータスアップデートを行うことも可能です。
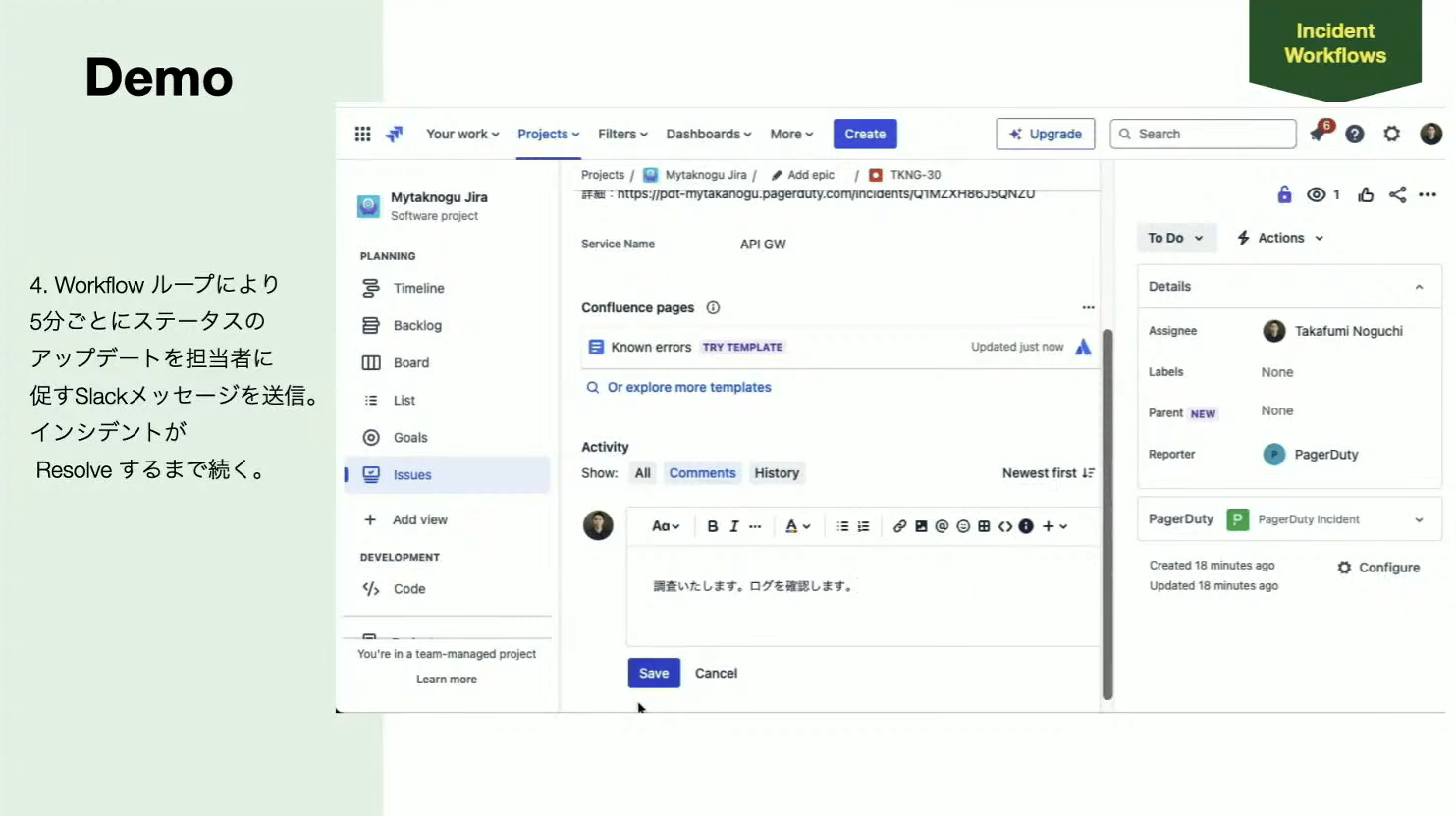
Noguchi:このデモはインシデントがResolveするまで続きますが、今回はここで止めて、次にインシデントワークフローの実際の設定内容をお見せします。左側のConditional Triggerでは、カスタムフィールドをトリガーにして、インシデントコマンダーを設定したり、タスクを割り当てたり、先ほど出てきたようなSlackのメッセージを追加したり、ディレイを発生させたりしています。
右側のManual Triggerでは、「ワークフローを実行してください」というボタンを押したときに、Jiraのチケットが作成され、50分間5分ごとにステータスアップデートを促すといった内容が設定されています。
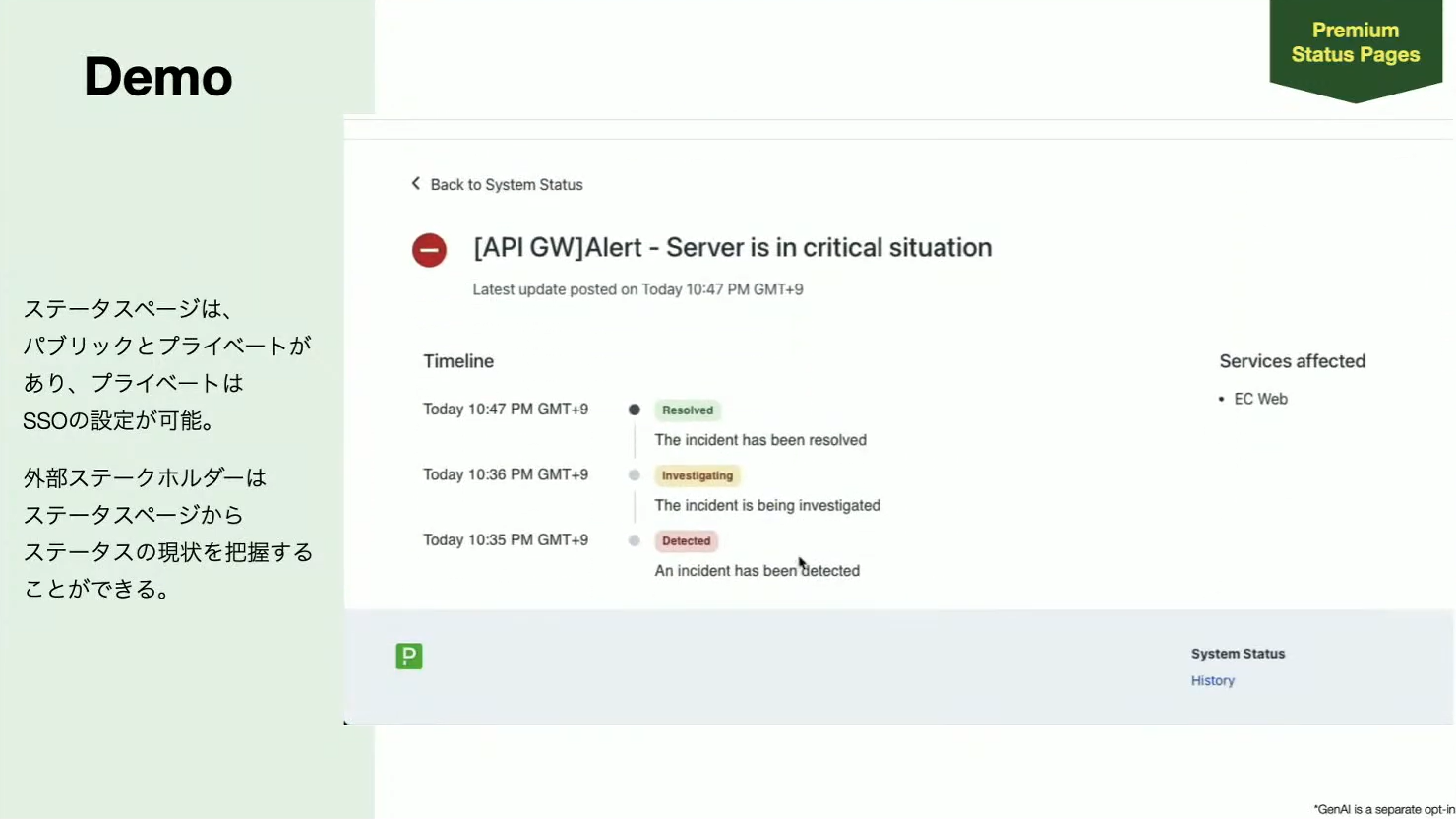
Noguchi:続いて、外部向けにインシデントの状況を伝えるステータスページです。パブリックとプライベートがあり、プライベートだとSSOの設定ができます。一部の方だけに見せたいという制約がある場合はプライベートで、そうでない場合はパブリックを使えばURLを知っている方全員が状況を把握できます。
例を見ていただくと、APIのゲートウェイで何か問題が起こっていて、そこに関係するビジネスのサービスで障害が起こっていると出ています。ここにはハイレベルな情報だけが載っていて、どこで検知されてどのタイミングで調査が始まったか確認でき、調査が進んで解決したらそれが反映されるようになっています。
Noguchi:そして、皆さんが気になっているであろうJeliですね。EIMが有効になっていると、左上のメニューに「Jeli Post Incident Review」が出てきます。先ほどのインシデントをSlackからインポートして使えるようにしました。ここでは、例えば誰が担当していたか、どのチャネルからインポートしたか、開始日から終了日などの情報が見られます。
Narrativeというメニューでは、解決までにどのようなプロセスを踏んだかがわかり、ここでポストモーテムの情報をよりリッチにしていく作業を行います。Detection(検知)、Diagnosis(診断)、Repair(修正)、Key Momentの4つが示されています。Key Momentというのは、解決のためのアクションを起こしたタイミングですね。
Slackからインポートした内容をチェックしながら、この4つのカテゴリから選択し、タイトルやサマリーを追加します。そうすると、実際にその期間、例えばエラーを見つけるために調査をしていたのか、それともエラーを発見したタイミングなのかといった形で、時間を分けて詳細に記録することができます。
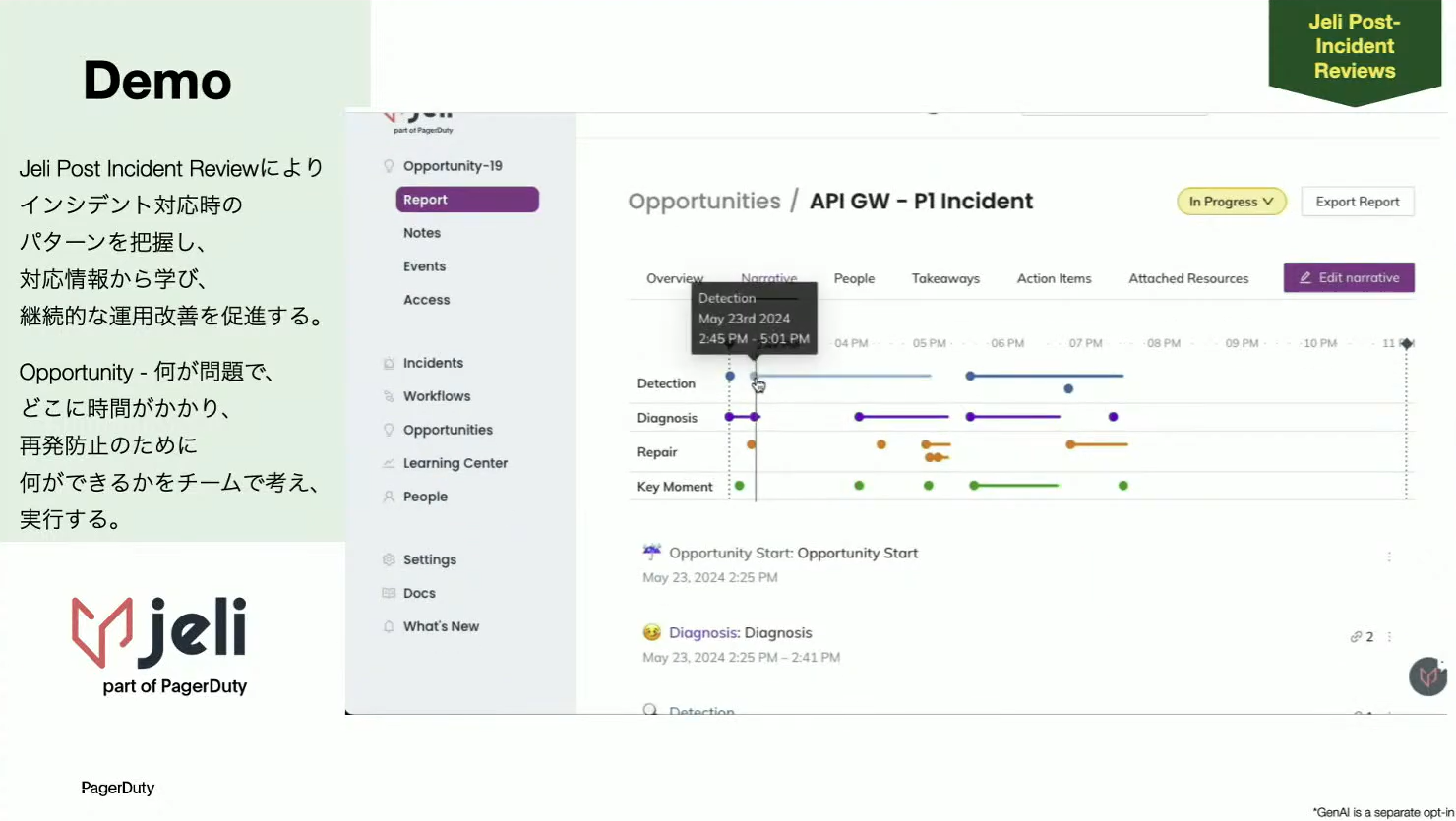
Noguchi:MTTRだけを見ていると中身はよくわかりませんが、ここまでブレークダウンして、チームでしっかりと情報を残すと、次に見たときに中身がよくわかります。例えば、Detectionにすごく時間かかったインシデントがあったとき、そのプロセスに何か問題がありそうだと、次の改善につなげていくことができます。あとは、ポストモーテムは読んでいて面白くないので、できる限りリッチにしようという意図もあります。
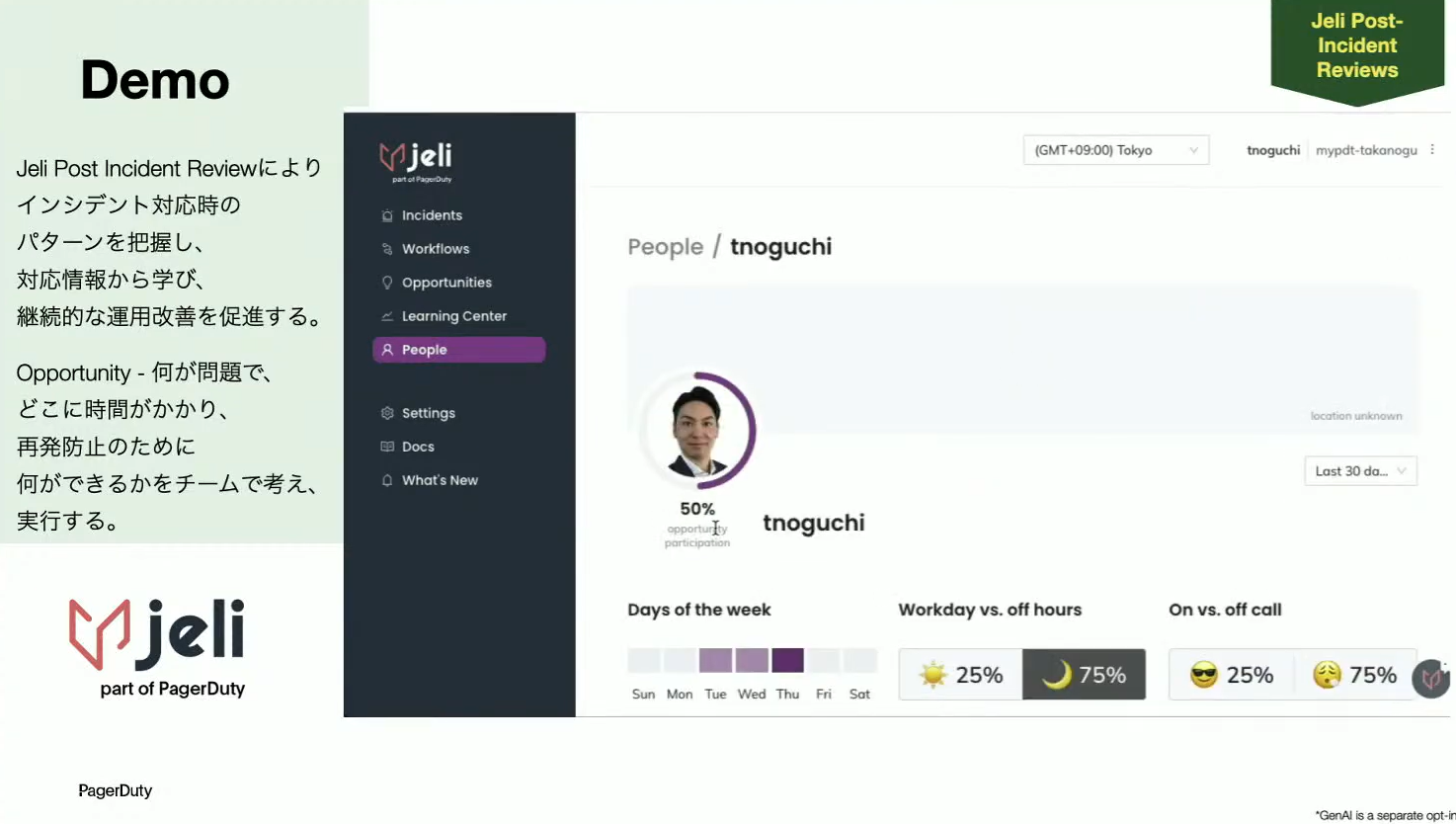
また、Peopleを見ると、その担当者の稼働時間や、今までどういったインシデントに対応していたかなどが表示されます。特に稼働が濃い曜日などもわかるので、それを考慮してスケジュールを組み直すなど、改善のプロセスにもつなげられます。
Noguchi:最後にまとめです。ここまで、インシデントレスポンスからインシデント管理に移行した背景や、EIMの機能について説明してきました。PagerDutyはオペレーションエクセレンスの追求や、継続的改善とプロセス最適化の実現、データドリブンな意思決定に取り組んでいきます。
まだまだPagerDutyの進化は続きます。来年に向けて、面白い機能がたくさんリリースされる予定なので、ぜひこれからも動向をチェックいただければと思います。本日はありがとうございました。
PagerDutyに関するFindy Toolsの紹介・レビューはこちら
https://findy-tools.io/products/pagerduty/3





