



【アーキテクチャConference 2025】Dress Codeが挑む、グローバルなコンパウンド戦略を支えるモジュラーモノリスとドメイン駆動設計
2025年11月20日・11月21日に、ファインディ株式会社が主催するイベント「アーキテクチャConference 2025」が、ベルサール羽田空港にて開催されました。
20日に行われた本セッションには、Dress Code株式会社のテックリード河村勇樹さんが登壇し、グローバル展開を前提としたコンパウンドプロダクト開発におけるモジュラーモノリスとDDD(ドメイン駆動設計)の活用方法を紹介しました。スタートアップの高速開発と堅牢なアーキテクチャの両立を目指す方にとって、実践的なヒントが得られる内容です。
■プロフィール
河村 勇樹(かわうそ)
Dress Code株式会社 Product & Technology テックリード
2019年に新卒で大手事業会社に入社し、航空気象サービスの開発に携わる。2021年にレバレジーズ株式会社に中途入社。レバテックCTO室のテックリードとして「レバテック」の開発・組織を牽引。レバテックのリアーキテクトやTiDBの導入を推進。2024年11月にDress Code株式会社に中途入社。アーキテクチャを中心にフルスタックに開発。ドメイン駆動設計やCQRS、Event Sourcingに挑戦中。採用や技術広報・組織設計にも携わる。趣味はお酒とゴルフとカワウソ鑑賞。
Dress Codeの事業・プロダクト紹介
河村:Dress Code株式会社は、2024年9月に設立して2025年4月に正式創業した会社になります。7月の開発生産性カンファレンスのアンケートでは、「知っている」と回答いただいた方が5%しかいませんでした。ただ、今年はさまざまなカンファレンスに出させていただいて、少しずつ認知度が上がってきていると感じています。
私たちの特徴として、初期フェーズから5カ国で事業展開をしています。日本、インドネシア、ベトナム、タイ、シンガポールです。なかなかめずらしい取り組みだと思いますので、迷ったところや、アーキテクチャ上の工夫についてお話しできればと思います。
私たちが挑戦しているのは、グローバルという領域に対してのワークフォースマネジメントです。従業員が入社してから退職するまでに発生する業務イベントに関わる領域ですね。採用、労務、プロジェクト管理などを含めて、ワークフォースマネジメント領域と呼んでいます。
私たちが解決したいのは、会社の部門間の摩擦問題です。たとえば、採用だとこういうツールが入っていたり、労務だとこういう仕組みが入っていたりして、局所的には最適化されているかもしれません。しかし、いざ部門間の連携をしようとしたときに、連携のコストが大きかったり、仕組みを作ろうと思ってもなかなかできないという問題があります。私も今までの会社でこうした問題を見てきました。
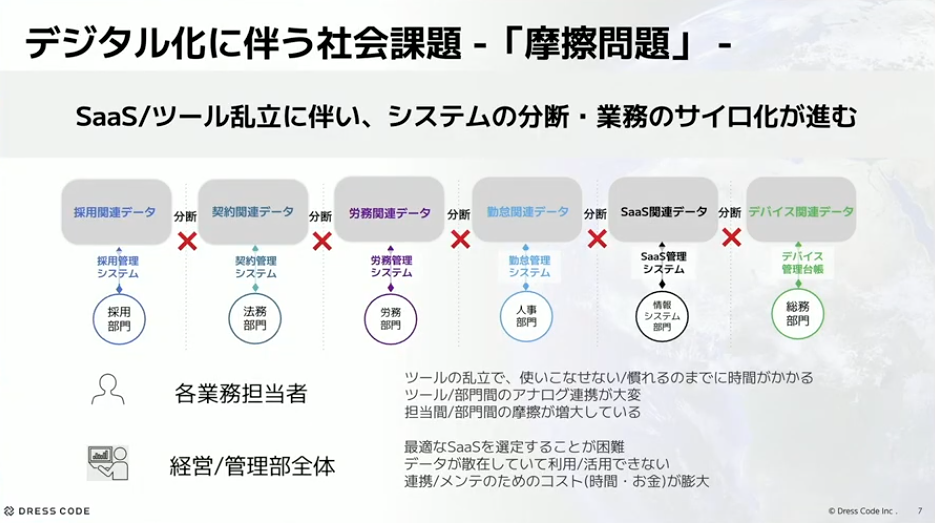
河村:そこでDress Codeでは、従業員ライフサイクルを全て完結できるようなプロダクトを作ろうとしています。たとえば、従業員が入社してから採用の手続きがあって、入社手続きがあって、アカウントが自動発行されて、デバイスの備品付与がある。本当に部門をまたいだところのライフサイクルを一つで完結できるようなプロダクトを提供して、「働くを変えて最高のオペレーションを提供する」ということを目指しています。
プロダクトの全体像としては、IT Forceが情シス向けのシリーズ、HR Forceが人事部向け、GA Forceが総務向けというように展開を考えています。この中で中心となるのが、プラットフォームケイパビリティというものです。これは、プロダクトにおけるデータベースやミドルウェアを含めた共通基盤です。私たちはコンパウンドプロダクトにおける価値を提供するためのエンジンのような捉え方をしています。

河村:一番下の方にCoreDBというデータがあり、その上にオペレーションエンジン、つまりワークフローエンジンのようなものがあります。さらに、契約の管理、アカウント認証、権限と役割といった仕組みが共通基盤の上に乗っていて、その上にプロダクトを横展開していく形を初期段階から進めています。基本的にプロダクトを作る上で共通基盤がすでにある前提で進めているのが、Dress Codeの特徴です。
そうした中で、私たちは約1年間の開発期間で15個以上のプロダクトをリリースしてきました。そろそろ20個を超えるところまで見えてきています。これだけの速度で開発できるのはなかなかないと思いますので、この辺りの話に興味があればぜひお声がけください。

今日、お話しすること
河村:7月に行われた開発生産性カンファレンスでは、開発生産性を高めるためにエンタープライズアーキテクチャをやっているというお話をしました。アーキテクチャは地図の役割を果たすもので、全体の方向性や目的地を示すものであったり、複雑な地形をナビゲートするガイドになったり、共通の地図になったりします。さらに言えば、AIエージェント活用においては、プロダクト開発を成功に導く羅針盤になるのではないかと考えています。

河村:現状と目標を整理しつつ、プロダクト特性やアーキテクチャ特性を特定しながら、その中で必要なものを選び抜くという活動をやっています。前回の登壇では抽象的な話が中心でしたが、今日は具体的なお話ができればと思っています。
その中で、モジュラーモノリスとDDDというお話が出てきます。モジュラーモノリスについては、現在モノリスでコンパウンドプロダクトをやっているという点と、モノリスで苦労するUIとドメインをどうやって分離しているかという点をお話しできればと思います。DDDについては、戦略・戦術といろいろありますが、今日は集約にフォーカスを当ててお話しできればと思っています。
モジュラーモノリスの活用と工夫
河村:まず、なぜモジュラーモノリスなのかというお話です。理由は3つあります。1つ目はモノリスとしてシンプルさを維持したいこと。2つ目は各プロダクトの独立性を担保したいこと。3つ目は組織としてのスケーラビリティも取りたいということです。
モノリスだとデプロイ単位も一つになりますし、データスキーマやトランザクションの管理も楽です。その意味で、モノリスがいいと考えています。また、独立性担保という意味では、ドメインの責任範囲を明確化したり、特定のモジュールに責務を負わせるという意味でカプセル化もできます。こうしたメリットを取りながら、さらに認知負荷を分散させてプロダクトごとに組織をスケールできるようにということで、モジュラーモノリスを採用しています。
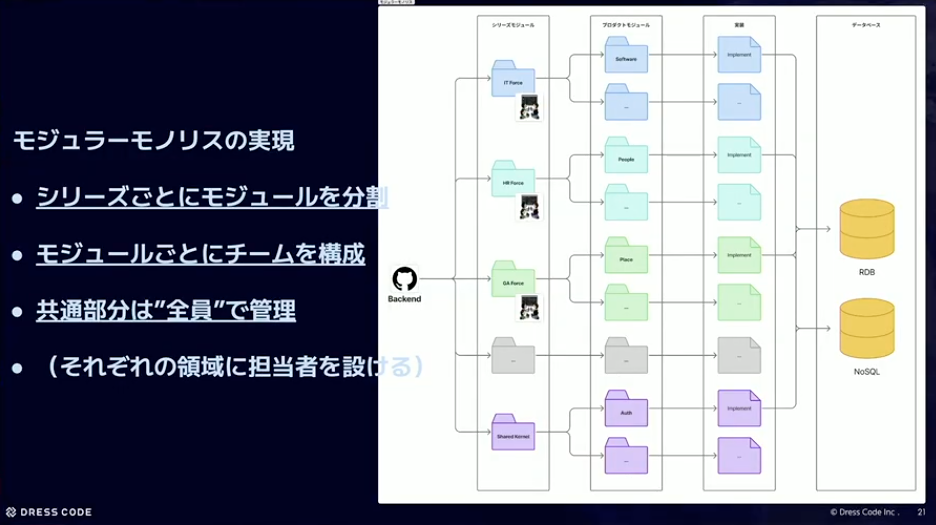
モジュラーモノリスの実現について説明します。先ほど出てきたIT Force、HR Force、GA Forceというシリーズごとにまずモジュールを切っています。そこにチームがいます。IT Forceチーム、HR Forceチーム、GA Forceチームという形です。一番下の共通部分は全員でやっていますが、全員が全部やるのではなく、ある程度担当者をつけて「このエンジンは誰々」という形で、共通部分は責任を個人に当てて進めています。
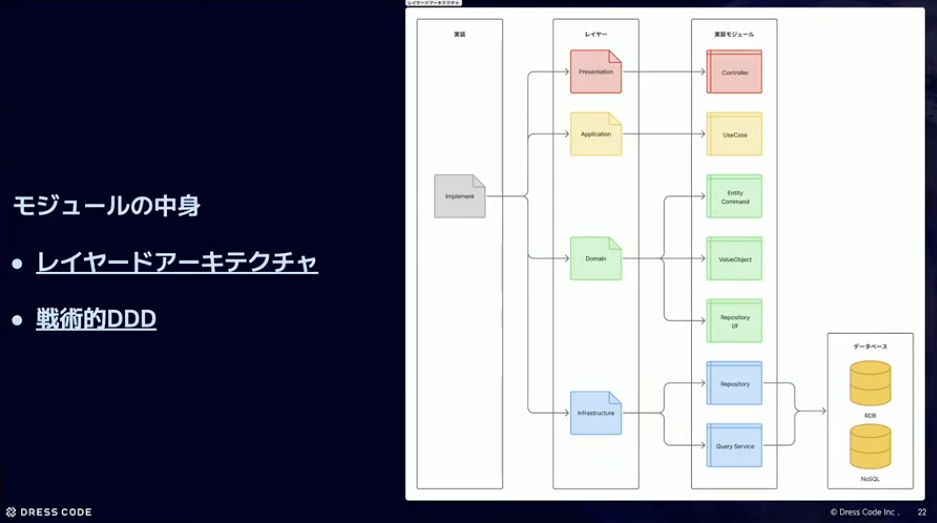
河村:モジュールの中身はどうなっているかというと、基本的にはレイヤードアーキテクチャと戦術的DDDというところで、依存関係の方向をきちんと定義してドメインに依存するようにやっています。
河村:モジュラーモノリスで困ったことが3つありました。1つ目はモノリスにおけるUI設計とドメイン設計をどうやって分けるか。2つ目はDBをモジュールごとに分けるべきかどうか。3つ目はモジュール間連携をどうしようかという悩みです。今日はこの3つについてお話しします。
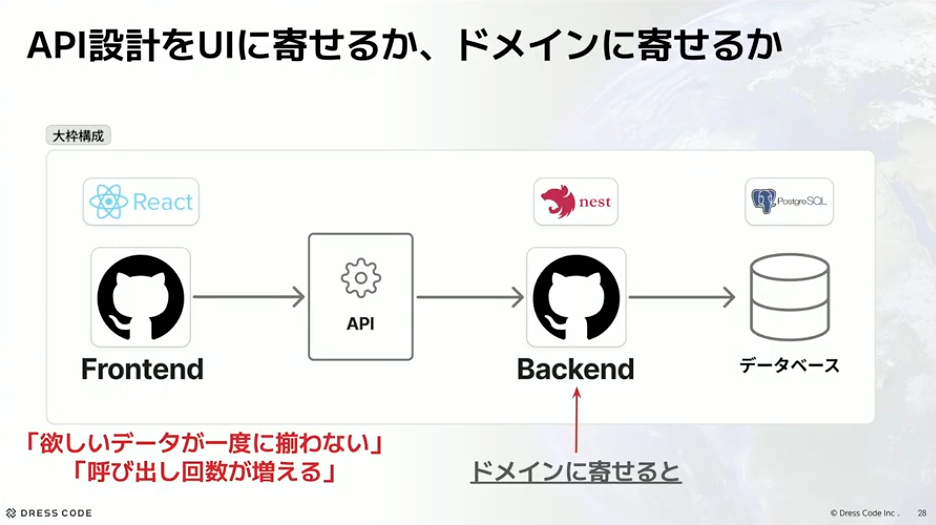
まず、モノリスにおけるUI設計とドメイン設計の切り分けについてです。API設計をUIに寄せるか、ドメインに寄せるかという話になります。
フロントエンドのAPI設計をUIに寄せると、バックエンドのアプリケーションレイヤーがDBへのCRUDを行うだけの実装になりやすいです。トランザクションスクリプトのように書かれて、保守性が高いかというと、フロントは使いやすいけどバックエンドはどうかな、という印象があります。
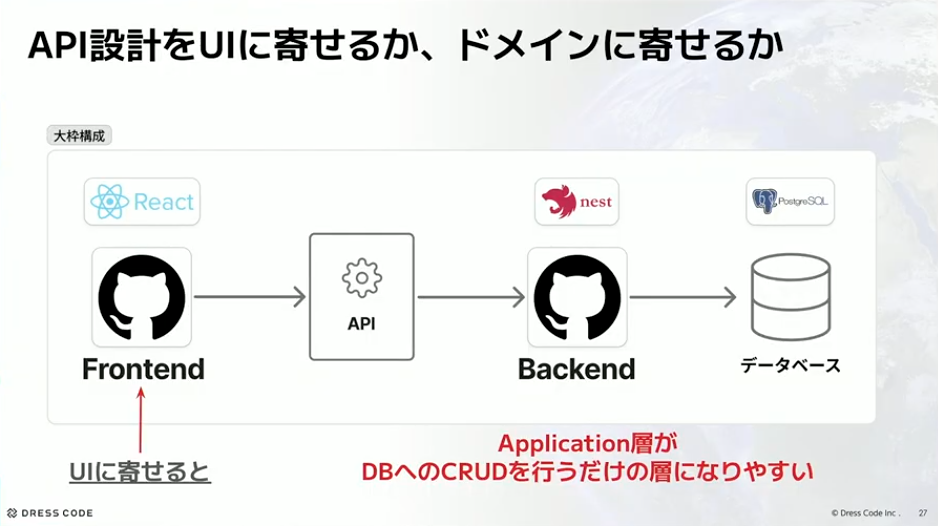
河村:逆にドメイン、つまりバックエンドに寄せていくと、フロントエンドは集約に対するAPIをいろいろなところから叩いて揃えなければいけないので、「欲しいデータが一度に揃わない」「呼び出し回数が増える」といった問題が出てきます。
河村:私たちはどうしているかというと、まずUIに寄せてAPI設計をしましょうと決めています。理由はシンプルで、フロントエンドに必要なデータはいろいろなパターンがあるので、取りやすいように定義しましょうとしています。
ただ、これをやるとアプリケーションレイヤーがCRUDを行うだけのレイヤーになりやすく、ドメインを表現するところやビジネスロジックを表現するレイヤーを見失いがちです。そこで、UIとドメインの設計思想も分離してしまえと思って、ReadとWriteを分離しています。
Readは基本的にクエリサービスを使って、Writeはドメイン経由にしようねという形でやっています。APIは基本的にはUIに寄せているのですが、そこから下はReadの場合はクエリサービスを呼んで、Writeの場合はドメインの方を呼ぶという形で完全に分離しています。
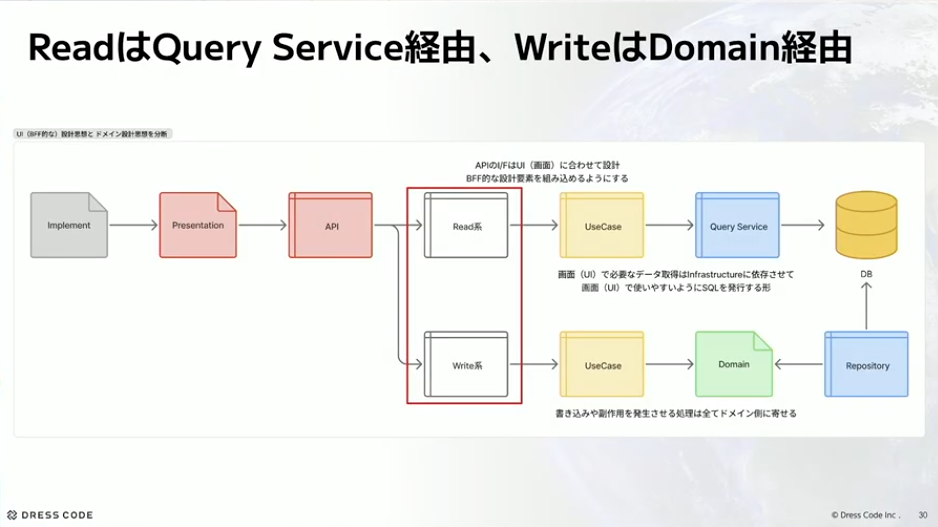
河村:世の中でいうとCQRSっぽいという話が出てくるのですが、厳密なCQRSではなく軽量CQRSのようなもので、データベースを分けるようなことはやっていません。Readはクエリ、Writeはコマンドというイメージを持ってもらえるとわかりやすいと思います。
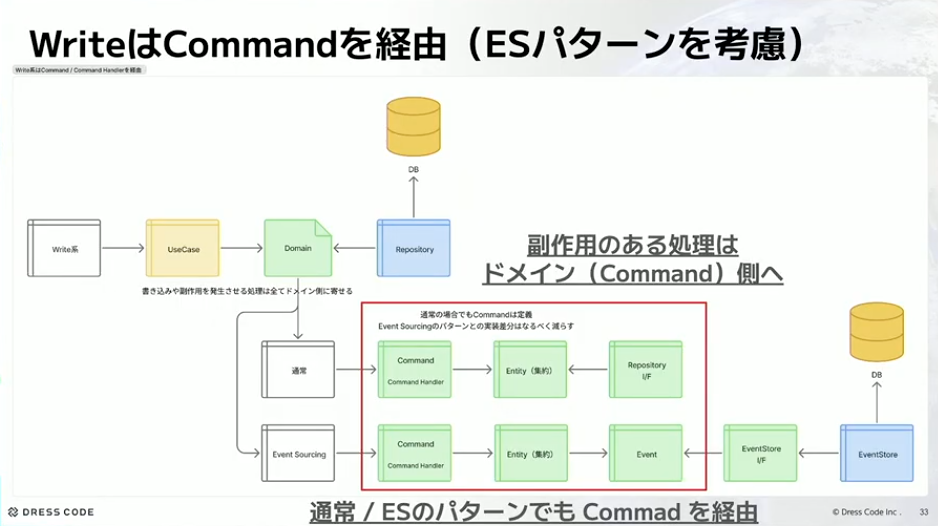
Writeはコマンド経由という話ですが、私たちはイベントソーシングも使っています。イベントソーシングの場合と通常の集約を取り出して永続化するパターンとを、バラバラにやるぐらいだったら揃えてやりたいということで、副作用のある処理は基本的にコマンドを経由してやるようにしています。ユースケースから見たときの入り口は一緒になるように実装しています。
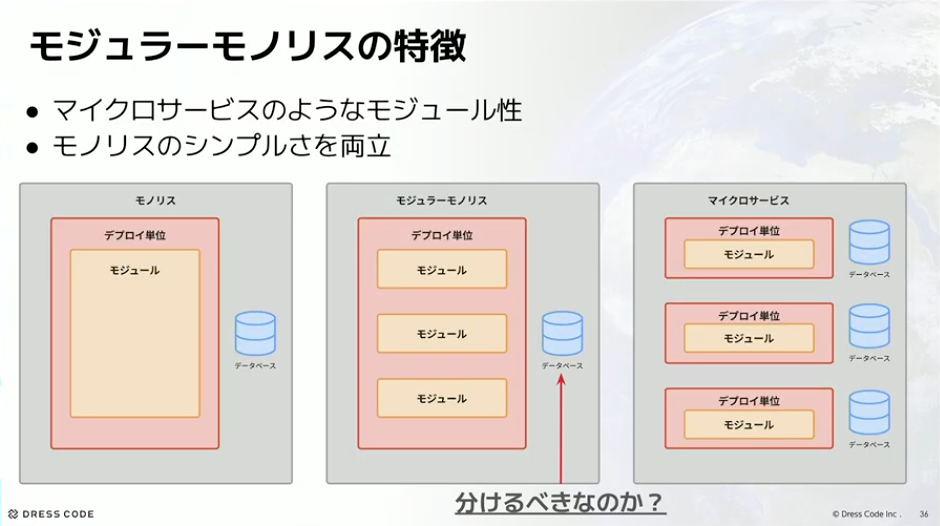
河村:次に、スキーマをどういうふうに分けていくべきかという話です。モジュラーモノリスの特徴として、マイクロサービスのようなモジュール性とモノリスのシンプルさを両立できるというものがあります。マイクロサービスだとデプロイ単位がそれぞれ分かれてデータベースも分かれています。モノリスだとデプロイ単位もデータベースも1つです。では、モジュラーモノリスのこのデータベースはどうするべきなのかというのが、よく出てくる悩みです。
河村:一般的には、同じDB内でスキーマを分離するのが推奨だと考えています。モジュールが1つのデータベースを共有して、各モジュールに専用のスキーマという論理的な名前空間を割り当てるということですね。理由は3つあって、分離のバランス、運用効率、柔軟性です。名前空間を分ければモジュール間のデータアクセスを制限しやすいですし、1つのDBで済むのでバックアップや監視も楽です。将来的にマイクロサービス化する際もスキーマだけ切り出せば比較的スムーズにできます。
ただ、私たちは分割していないです。スキーマすらも。モジュラーモノリスですが、DBはまったく分割していません。なぜ分割しないのかというと、「現段階におけるモジュール分割が適切である自信がないから」です。マイクロサービスもそうだと思いますが、一度分けたら元に戻すのはとても大変です。

河村:私たちは創業してまだ半年ちょっとなので、「やっぱりこうしたい」となったときに、分割されていることで変更コストが高くなるぐらいだったら分けない方がいいと考えています。また、分けたら分けたで管理コストも上がります。マスターデータのような共通データの管理や共有が面倒になってきます。さらに、不整合なデータを作らないためという意味で、1つのスキーマにあれば外部キー制約も利用しやすいと思っています。異なるスキーマ間でも外部キー制約を貼ることはできますが、それは分離性の低下につながり、元も子もないと思っています。
これをやっていくと、「ではすべてのデータに自由にRead/Writeされていいのか」という問題が出てきます。私たちは分割しない代わりにデータのオーナーは定義しようねということをやっています。オーナーであるモジュールからのRead/Writeを基本として、すべてのデータを自由に直接Read/Writeさせない仕組みを作っています。

河村:理由は明確で、不整合なデータを作らないことを優先したいからです。他のモジュールが勝手にデータをWriteしてしまうと、必要なビジネスロジックを通過せずにデータができてしまうことがあります。そこを防ぎたいのと、分離性を落とさないことも考慮しています。いろいろなところがRead/Writeしていると、コード自体も分散していくので、そういったことを避けたいと考えています。
では、モジュールをまたいだ連携はどうやってやるのかという話です。全てのデータに自由にRead/Writeされる可能性というのは、たとえばIT ForceとHR Forceという別のモジュールがあったときに、IT ForceからHR Forceが持っている「People」というデータにアクセスしたり書き込みしようとしたりするケースです。さすがにこれはよくないですよね。
河村:そこで今は、直接書き込むのではなく、HR Forceが定義しているアダプターというモジュールの中にあるものを使って読み込もうとか、先ほど出てきたコマンドを経由して書き込もうといった形でやっています。
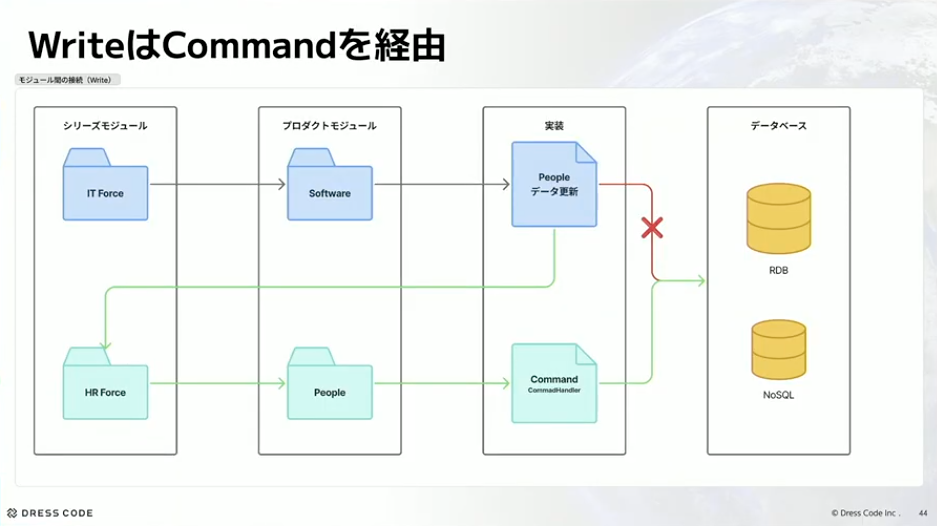
河村:自由にデータをRead/Writeさせないと良いことが2つあると思っています。1つはコードレベルでデータを守ることができること。もう1つはモジュール間のインピーダンスミスマッチと向き合いやすくなることです。「People」のデータを更新したいときに、もちろんHR Force側のコマンドに合わせた変換が必要になりますが、この変換と向き合いやすくなります。データを直接書き込むよりは、ちゃんと必要な定義をもとに変換した方が抽象化もできるし、向き合いやすくなると思っています。
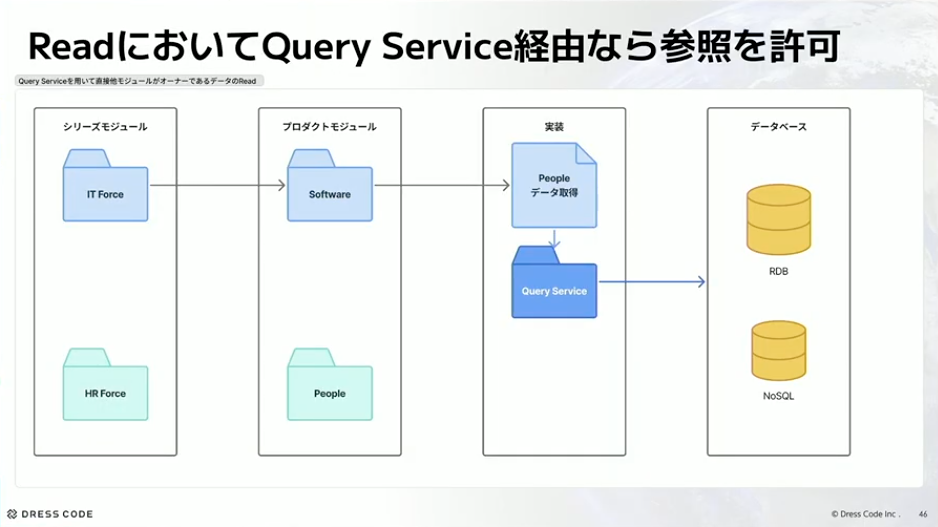
とはいえ悩ましいこともあって、アダプター経由だとデータ取得がとても非効率になります。ページネーションなども含めると複雑になるので、どうしても複雑度や効率的にも直接取得したくなるケースがあります。そこで、取得に関しては一旦クエリサービスでいいのではないかというのが今のパターンです。クエリサービス経由なら直接引っ張ってきて1発で取れるようにしてもいいかなと考えています。ただ、書き込みはさすがに書き込まれて困るので、基本的にはコマンド経由でという考え方でやっています。
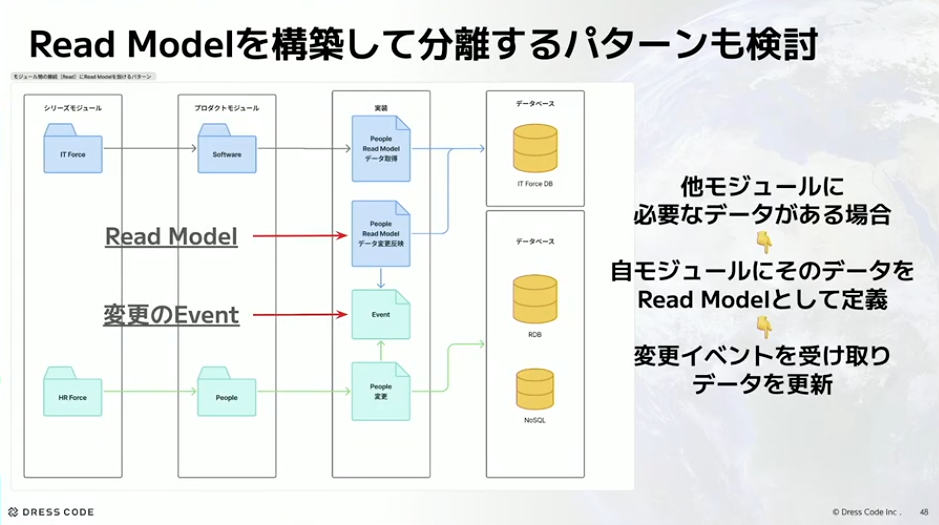
河村:ただ、これだと結局HR Forceがオーナーであるべきところの参照が外にあることになってしまうので、これを何とかしようということで、Readモデルを構築して分離するパターンも考えています。他モジュールに必要なデータがある場合には、自モジュールにそのデータをReadモデルとして定義して、変更イベントを受け取ったらデータを更新するようなパターンを検討しています。Dress Codeはイベントソーシングを使っているので、イベントをうまくサブスクライブできるような仕組みを作ってReadモデルに反映できれば、IT Force側がRead用のDBに反映しやすいし、データも取得しやすい形で作れるのではないかと考えています。
DDDにおける“集約”の活用
河村:先ほどコマンド経由でやっていますというお話の中で、通常のパターンとイベントソーシングのパターンがあり、その中で「集約」というものがすでに出てきていました。ここからは、その集約についてお話しします。
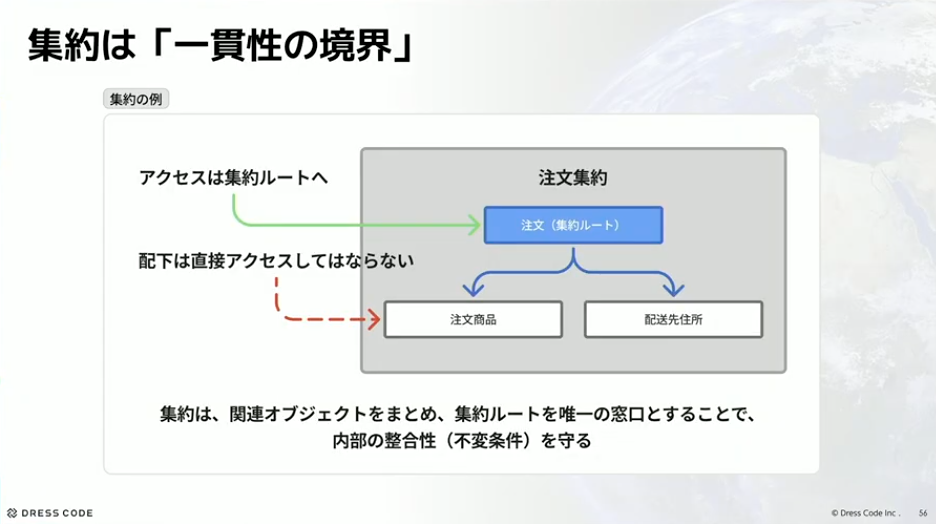
集約とは何かというところですが、定義を読みます。「データ変更の目的において単一のユニットとして扱われる」「その境界内に存在するオブジェクト群に対して、常に真でなければならない一連のビジネスルール、すなわち不変条件を保護する」こと、そして「集約の境界は、データベースのリレーションシップによってではなく、ビジネスルールに基づいて慎重にモデリング」されるものだということです。
まとめると、関連するデータとビジネスルールをひとまとめにした単位のことで、この単位の中でデータの整合性が常に保たれるように設計するものが「集約」です。集約は「一貫性の境界」と呼ばれ、たとえば注文集約というものがあったら、集約ルート経由で必ずアクセスして、配下の注文商品などには直接アクセスしないというやり方です。集約は関連オブジェクトをまとめ、集約ルートを唯一の窓口とすることで、内部の整合性や不変条件を守りましょうという設計パターンです。
河村:この集約を適切に分割するには業務理解が必要です。DDDの戦略の文脈でもよく話されることですが、理由が3つあります。1つ目は一貫性の境界を正しく定義するため。2つ目は複雑性を抑えるため。3つ目は変更容易性を高めるためです。
1つ目に関しては、業務理解がないと一貫性が失われる分割になって、データ競合や不整合が発生したりします。業務の因果関係やルールを知らないと境界が曖昧になり、信頼性も低下します。私もエンジニアリングをやりながらDDDと向き合うことが多かったですが、なんだかんだビジネスサイドのことを知らずに勝手に自分たちで集約を定義してやってきたこともありました。それでよかったことはあまりなかったというのが正直な感想です。
2つ目については、集約は分割しすぎるとクエリや更新が複雑になりますし、一方で大きすぎてもパフォーマンスやメンテナンスが大変になります。理解不足で分割すると変更が一箇所に収まらなくなってしまうので、ちゃんと業務理解を深めた上でやるのが集約です。ドメインエキスパートとの対話を通じて、業務の「不変のルール」と「変動する部分」を区別する必要があります。
つまり、集約は技術的なデータのまとまりではなく、業務ルール上一貫性を保つべき情報のまとまりです。
では、Dress Codeではどうしているかというお話をしていきます。Dress Codeには「Graph」と呼ぶ概念があります。これはDress Codeオリジナルの概念です。
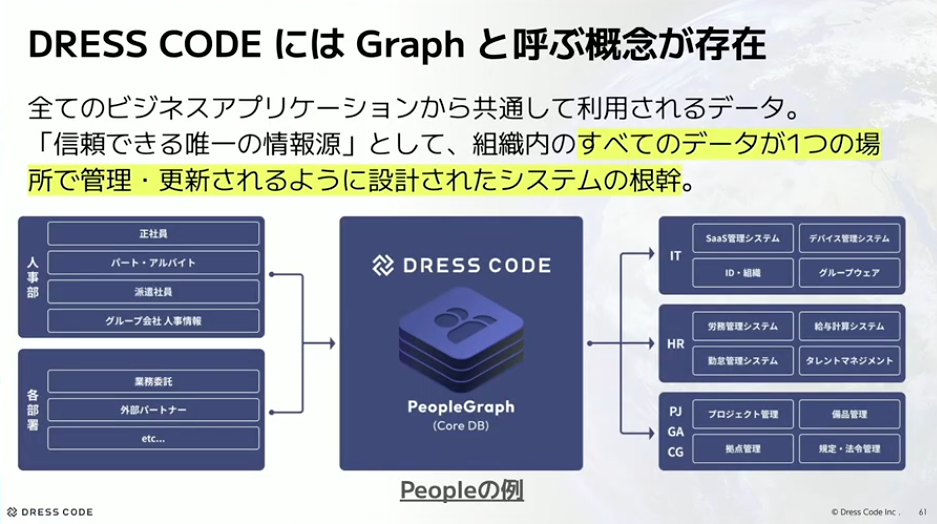
河村:Graphとは、すべてのビジネスアプリケーションから共通して利用されるデータで、信頼できる唯一の情報源、つまりSSOT(Single Source of Truth)です。組織内のすべてのデータが1つの場所で管理・更新されるように設計されたシステムの根幹です。たとえばPeopleの例でいうと、人事部やIT、HRなどから参照するデータはすべてGraphにアクセスしましょうというものになります。
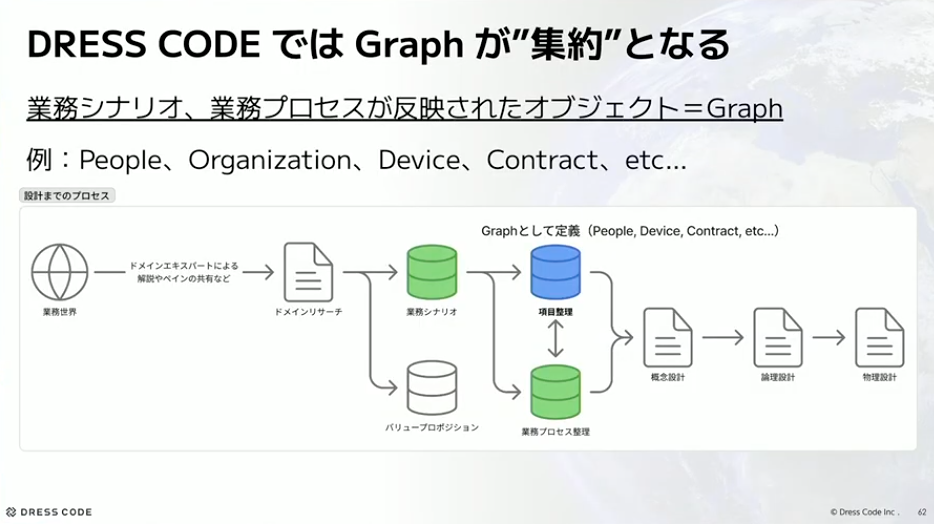
なぜこれが集約となるかというと、プロセスにあります。設計までのプロセスの中で、まず業務世界があって、そこからドメインリサーチをして業務シナリオとバリュープロポジションを考えます。そこから項目整理、業務プロセス整理をして、概念設計、論理設計、物理設計へと流れていきます。この項目整理されたものが私たちのGraphになるので、業務シナリオも反映されているし、業務プロセスも反映された項目になります。つまり、それが私たちにとってGraphが集約になるということです。業務理解ももちろん必要ですし、業務プロセスが反映されたものになるので、それが境界になります。Dress Codeのプロダクトとしてもいいものだと思っています。例としては、People、Organization、Device、Contractなどがあります。
河村:では、なぜ集約が必要なのかという話に入っていきます。理由はシンプルで、ドメイン(データ)の整合性を守るために重要だからです。
集約を適用すると整合性を守れる要因についてお話しします。集約ルートは集約のエントリポイントとなるエンティティで、外部からはこのルート経由でしか内部のオブジェクトにアクセスできないようにするというのが、先ほどの一貫性の境界でお話ししたところです。大事なこととして、部分的な更新を許容しないということがあります。許容してしまうと、集約を通過せずに永続化されてしまい、ビジネスルールが集約に定義されているのにそれが通らずに永続化されてしまって、容易にデータの不整合ができてしまいます。基本的には集約ルートからすべてを進めましょうということです。

河村:なぜデータ不整合を回避できるのかというと、「原子的な変更単位」として扱うから回避できます。必ず集約を生成するというプロセスを強制させるというのがとても重要で、いわゆる制約です。集約ルートにバリデーションやビジネスロジックがあれば、不整合のある集約が生成されることは基本的にはなくなるはずです。部分的な更新を許容してしまうと、集約を経由しないでデータの永続化が可能になってしまいます。
特に私が気にしているのは、集約ルートとエンティティとの関係、その間にある制約が意外と守れていないことです。大体が直接内部にあるエンティティをそのまま作って永続化するというようなことをよくやっていると思いますし、よく見てきたのは、エンティティとリポジトリが1対1で作られている構成です。それぞれが1対1なので、それぞれで永続化されてしまい、結局守りたかった集約のルールを守れていないということはよくあります。
良い例としては、永続化のためにリポジトリを定義していて、必ず集約ルートから永続化を行うので、コントラクトエンティティは必ず生成されてから作られます。悪い例としては、内部にあるコンタクトタームエンティティをベースにリポジトリが作られているので、集約ルートのビジネスルールを適用せずにエンティティを永続化できてしまうという問題があります。

河村:AIの話とも絡めてお話しすると、AIにおいて制約を課すということがとても重要だと思っています。コード生成の精度を上げようと思ったら、制約を課すしかないと考えています。これは正直人間も一緒だと思いますが、DDDにおける集約には制約を課すということがあって、それは先ほどの「原子的な変更単位として扱って部分的な変更を許容しない」という制約です。
この制約があることで、AIが想定外の実装をしないように防ぐことができます。自由にどうぞ実装してください、レイヤードアーキテクチャでどうぞ、となると、大体エンティティとリポジトリが1対1で作られて永続化してという形になりがちです。ちゃんと集約のルールがあるのでこのとおりにやってくださいということで、不整合なデータができるような実装がなくなったり、今まで見たことのない実装が発生するのを防ぐことができると思っています。
集約の難しいところは、小さく保つことです。これは本当に難しいです。大きすぎても小さすぎても問題になります。大きすぎればロック競合や複雑化もありますし、不整合のリスクも一定あります。1つのトランザクション境界に、本来別々に変更されてもよいものが入ってくるからです。逆に小さすぎても、不変条件を侵害したりロジックが漏洩したりするので、小さすぎることも問題になります。
ここに対してDress Codeがどうしているかというと、Graphというものを使って進めています。私たちはこれを「一貫性を保つべき情報のまとまり」だと考えています。とはいえ、ビジネスやプロダクト、事業を考えてやっていても、集約のサイズ問題には常に向き合う必要があります。業務上、どうしても同一集約で取り扱いたいことは当たり前のようにあります。業務想定やユースケースを変更して境界を切ることはできるのですが、やっぱり一緒に取り扱いたいという境界は全然あると思っています。

河村:大きい集約を安易に分割してはいけないとも思っています。安易に集約を分けてしまうと、思わぬデータ不整合につながったり、想定していないところでプロダクトに影響するのではないかと考えています。
特にあるのが、同一集約(トランザクション)であるべきだった集約です。ロールバック的なことを考えたときに、本当はこの業務においてはこのデータは一緒に取り扱いたかったのに、別々の集約のせいで片方だけロールバックできていなくてデータ不整合が生まれる、というようなことは全然あると思います。ロールバック的なことを考えると、同一集約でいた方が断然楽だとも思います。
私たちは集約が大きいことをあまりネガティブに考えていません。何よりデータやドメインを守ることが最優先だと考えています。小さくしてパフォーマンスが良くなったとしても、不整合なデータができてしまうなら意味がないと考えています。ロック競合を含めたパフォーマンス課題は技術でなんとかします。DBのWriteがボトルネックになるなら、ReadWriteをDB含めて完全に分離してしまうCQRSを採用すれば、ロック競合もなくなるはずです。私たちは業務系をやっていますが、同期的にデータを保証する必要がほぼないので、イベントソーシングやCQRSが合うのではないかと考えています。

河村:AIにとっても大きい集約は悪ではないと思っています。これは個人的な意見ですが、大きいということは、人間やAIが読むコンテキストを考えたときに、1つに全部まとまっていた方が楽です。私たちが作っている集約にはものすごく大きいものもあります。1つのソースコードとしては大きいかもしれませんが、そこに全部まとまっていると考えれば、人間もAIも読むコンテキストが分散せずに済むので楽だと思います。むしろAIに実装してもらうときは効率よくできるのではないかとも考えています。
なので、無理して集約を小さく保つよりは、集約を適切に実装することを優先して、大きさやスケーラビリティ、AIの実装具合を見ながら集約の境界を調整していくのがいいのではないかと思っています。結局のところ、集約も「要はバランス」ですね。
まとめ
河村:まとめに入っていきます。まず、アーキテクチャは地図の役割であると私は思っています。理想形を定義しながら、今必要なアーキテクチャを定義して、その結果として今はモジュラーモノリスとDDDを活用しています。
モジュラーモノリスを活用する中で、モジュール内部はRead/Writeを分離しています。モノリスとしてのシンプルさを維持しつつ、各プロダクト(ドメイン)の独立性を担保しています。UIに寄せた設計思想とドメインの設計思想を分離しつつ、DB分割とモジュール間の連携は最適解を探しながらも、自由にRead/Writeさせない仕組みを作っています。
DDDにおける集約という「制約」で整合性を守っています。集約は業務ルール上一貫性を保つべき情報のまとまりで、Dress CodeではGraphという概念が存在しており、これを集約として扱って進めています。集約が大きいことをネガティブに考えないというのが私たちの今の考え方で、データやドメインを守ることを最優先に考えています。人間を含めたAIにとっても、大きい集約は悪ではないと考えています。今後、集約の大きさやスケーラビリティ、AIの実装具合を見ながら見極めていこうと思っています。
最後に、今日締めたい話があります。アーキテクチャは変更容易性で語られがちだと思いますが、私はドメインを守るという文脈でもアーキテクチャは重要だと思っています。データ整合性を維持し、破壊や改ざんのリスクを防ぐ「守りの仕組み」がアーキテクチャだと思っています。
また、業務プロセスにおいては「履歴」というデータもとても重要な資産になってきます。監査なども業務系は関わってくるので、そういったものも含めて履歴はとても重要な資産です。このデータも含めて守りたいなら、私たちはイベントソーシングがいいと考えて導入しています。
アーキテクチャは変更容易性だけでなく、データを「守る」目的においても重要ですという言葉を最後に、発表を終わりたいと思います。ご清聴ありがとうございました。

アーカイブ動画・発表資料
イベント本編は、アーカイブ動画を公開しています。また、当日の発表資料も掲載しています。あわせてご覧ください。
▼動画・資料はこちら
アーキテクチャConference 2025
※動画の視聴にはFindyへのログインが必要です。





