



【アーキテクチャConference 2025】社内外から"使ってもらえる"データ基盤を支えるアーキテクチャの秘訣
2025年11月20日・11月21日に、ファインディ株式会社が主催するイベント「アーキテクチャConference 2025」が、ベルサール羽田空港にて開催されました。
「開発したのに、データ基盤を使ってもらえない」──そんな悩みを抱えるデータエンジニアは少なくありません。21日に登壇した株式会社Hacobuの飯塚 大地さんと高橋 一貴さんは「使ってもらえるデータ基盤には、データ、システム、ユーザー、スキルの4つが必要」と語ります。本セッションでは、システム設計と組織づくりという二つの側面から、同社がどのようにして「使ってもらえるデータ基盤」を実現したのか、具体的な取り組み事例をご紹介いただきました。
■プロフィール
飯塚 大地(dach)
株式会社Hacobu
テクノロジー本部 CTO 室
SI、ASP、インターネットメディア系、小売系を経て、2024年4月より Hacobu に join。 FRONT、BACKEND、SRE、PjM と幅広く経験し、現職ではデータ分析基盤の立ち上げや運用の経験を活かし、データエンジニアとして物流ビッグデータにチャレンジ中。 普段はチキン南蛮エンジニアとして、ユーザーに多大に支えられながら勉強会コミュニティ Easy Easy を運営中。
高橋 一貴
株式会社Hacobu
テクノロジー本部 CTO 室
前職では移動ビッグデータの分析チームに所属し、人流変化やカーナビデータを活用した交通分析を担当。「モノの移動」への関心からHacobuに参画。現在は自社サービスの分析、各事業向けの分析・ダッシュボード提供、社内向けデータ利活用教育などに取り組む。
「使ってもらえる」データ基盤に必要な4つのもの
飯塚:本日は「社内外から"使ってもらえる"データ基盤を支えるアーキテクチャの秘訣」と題して、株式会社Hacobu テクノロジー本部 CTO室より、飯塚と高橋の2名でお話をさせていただきます。よろしくお願いいたします。
はじめに、タイトルにもある“使ってもらえる”という言葉の定義について認識を合わせたいと思います。
そもそも「使ってもらえる」とは、どのような状態を指すのでしょうか。

私たちは、システムやデータ基盤があるだけでは不十分だと思っています。ユーザーがいるだけであっても成立しません。データ、システム、ユーザー、そしてユーザーが持つスキル、これらが全て揃って初めて、データが活用され、「使ってもらえる」状態になるのではないかと考えています。
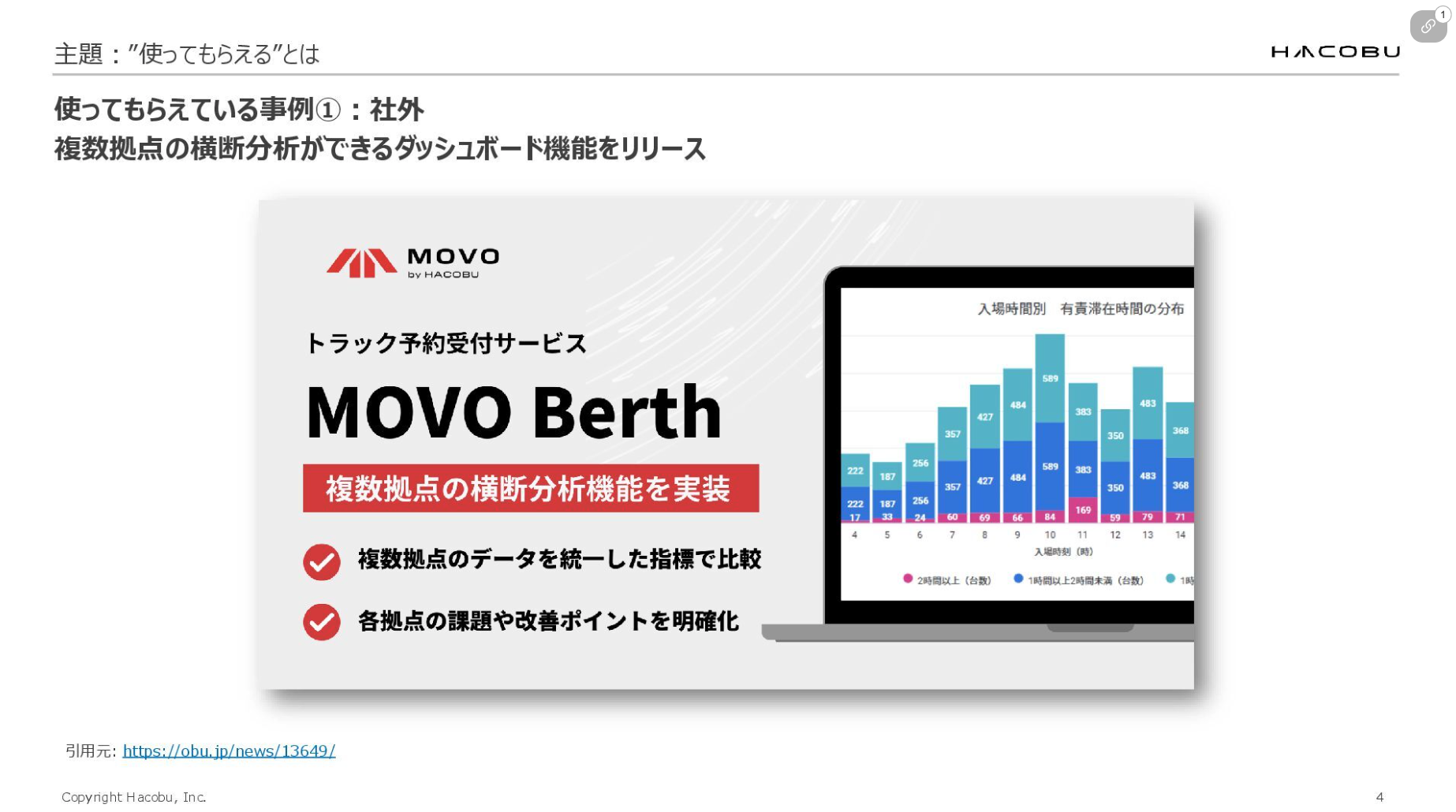
実際に使ってもらえているデータ基盤の事例もご紹介させてください。社外で使ってもらえている一例に、トラック受付予約サービス「MOVO Berth(ムーボ・バース)」があります。機能の1つとして「拠点横断アナリティクス」という複数拠点の横断分析ができるダッシュボード機能を提供しています。

また、データ基盤を利用してデータを利活用する際、データアナリストやデータチームが対応するユースケースが思いつくのではないでしょうか。しかし弊社では、データチーム以外のメンバーが自主的にデータ活用をする体制が整っています。社内のデータ活用事例については、ぜひnoteでご一読ください。
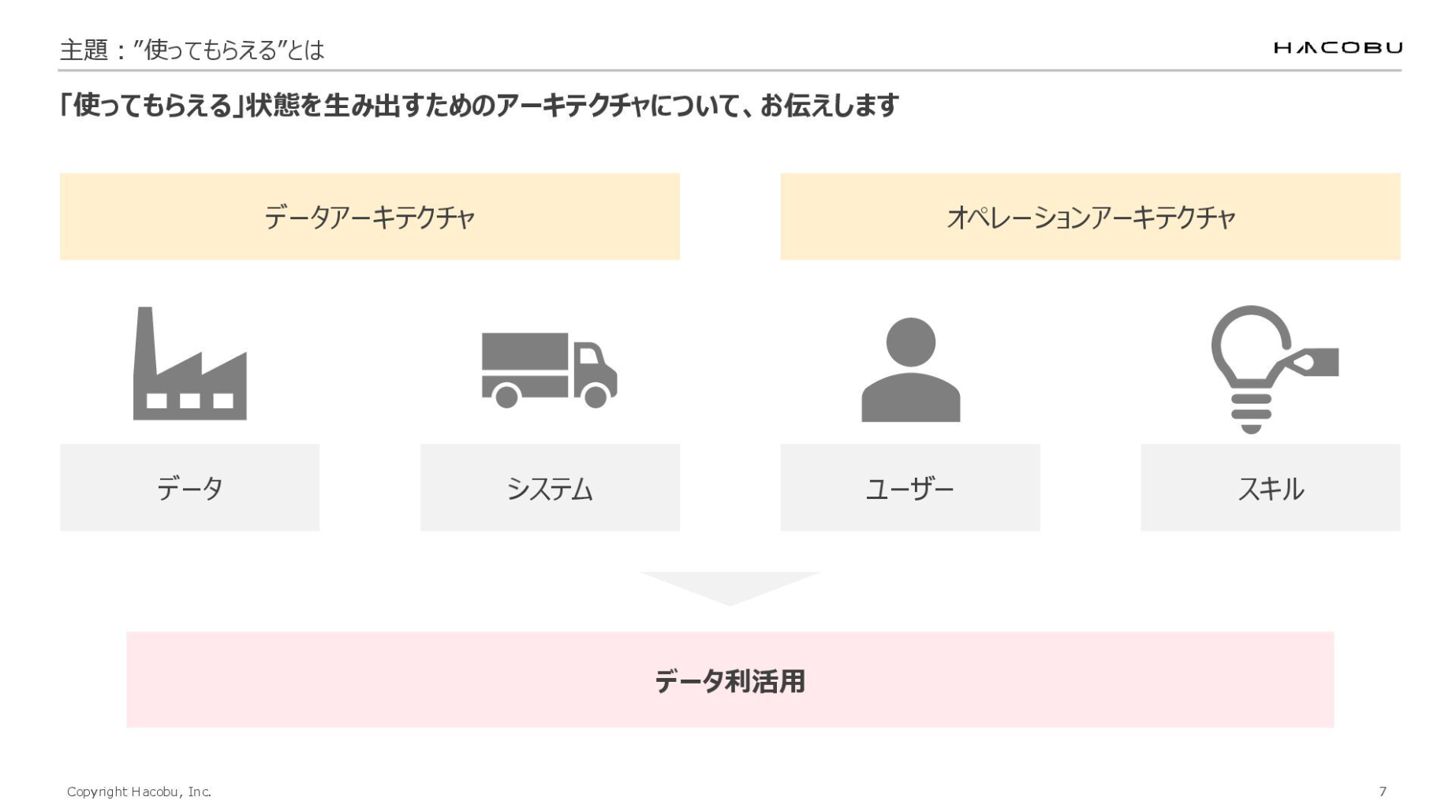
「使ってもらえる」状態を生み出すためのアーキテクチャについてお伝えするにあたり、データとシステムに関しては「データアーキテクチャ」、ユーザーとスキルに関しては「オペレーションアーキテクチャ」のそれぞれでお話しできればと思います。
本日は「使ってもらえるデータ基盤」の事例紹介を通して、皆さまが現場に持ち帰れるヒントになれば幸いです。

「時間がない」を打破する、シンプル・自動化・横展開の仕組み作り
飯塚:システムの話に移る前に、弊社がどのようなデータを扱っているかについて、事業説明も兼ねてお話しします。
Hacobuが挑む領域は「物流」です。物流領域は多数のステークホルダーが存在していることに加えて、業界固有のオペレーションなど、独自の構造課題を抱えています。
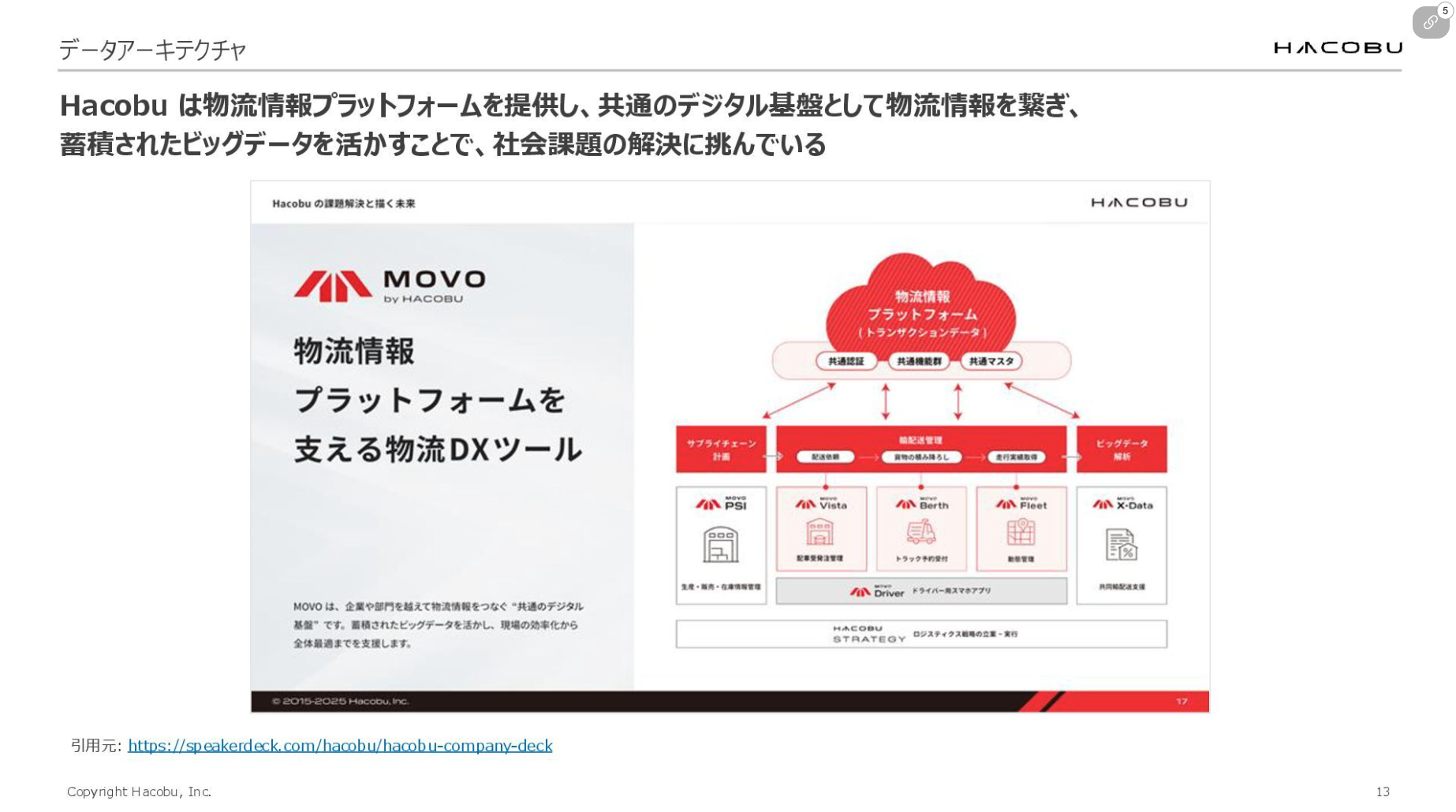
そこでHacobuは、物流DXツール「MOVO(ムーボ)」の提供を通して、共通のデータ基盤として物流情報を繋ぎ、蓄積されたビッグデータを活かすことで社会課題の解決を目指しています。
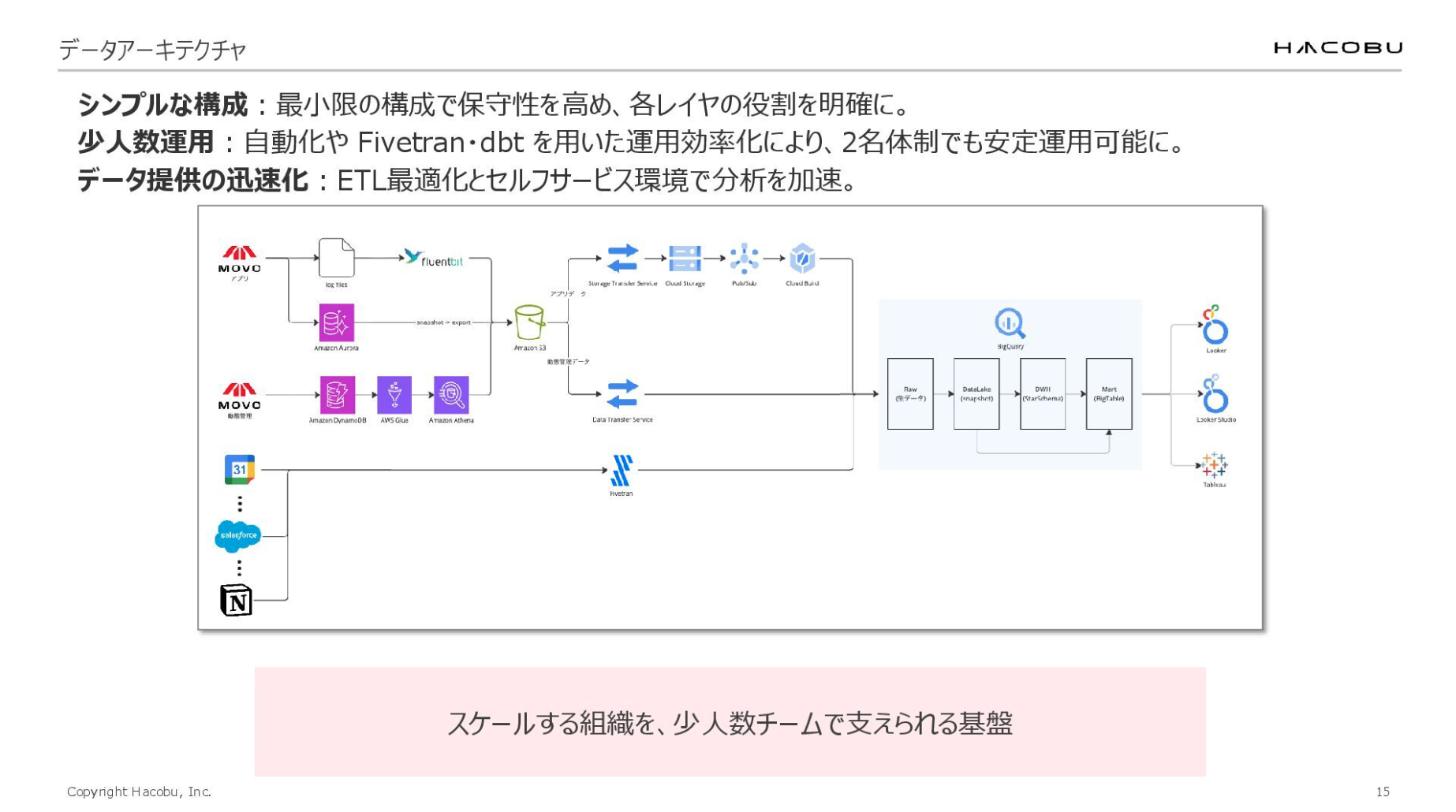
それでは本題に入ります。これはFindy Toolsに寄稿したデータアーキテクチャの図です。
MOVOのデータ分析基盤は Google Cloud 上に構築しています。データを連携させることで、ユーザーがBIツールを通じてデータを活用できる構成としています。
この構成には「シンプルな構成」「少人数運用」「データ提供の迅速化」という3つのポイントがあります。
認知負荷を下げるための「シンプルな構成」
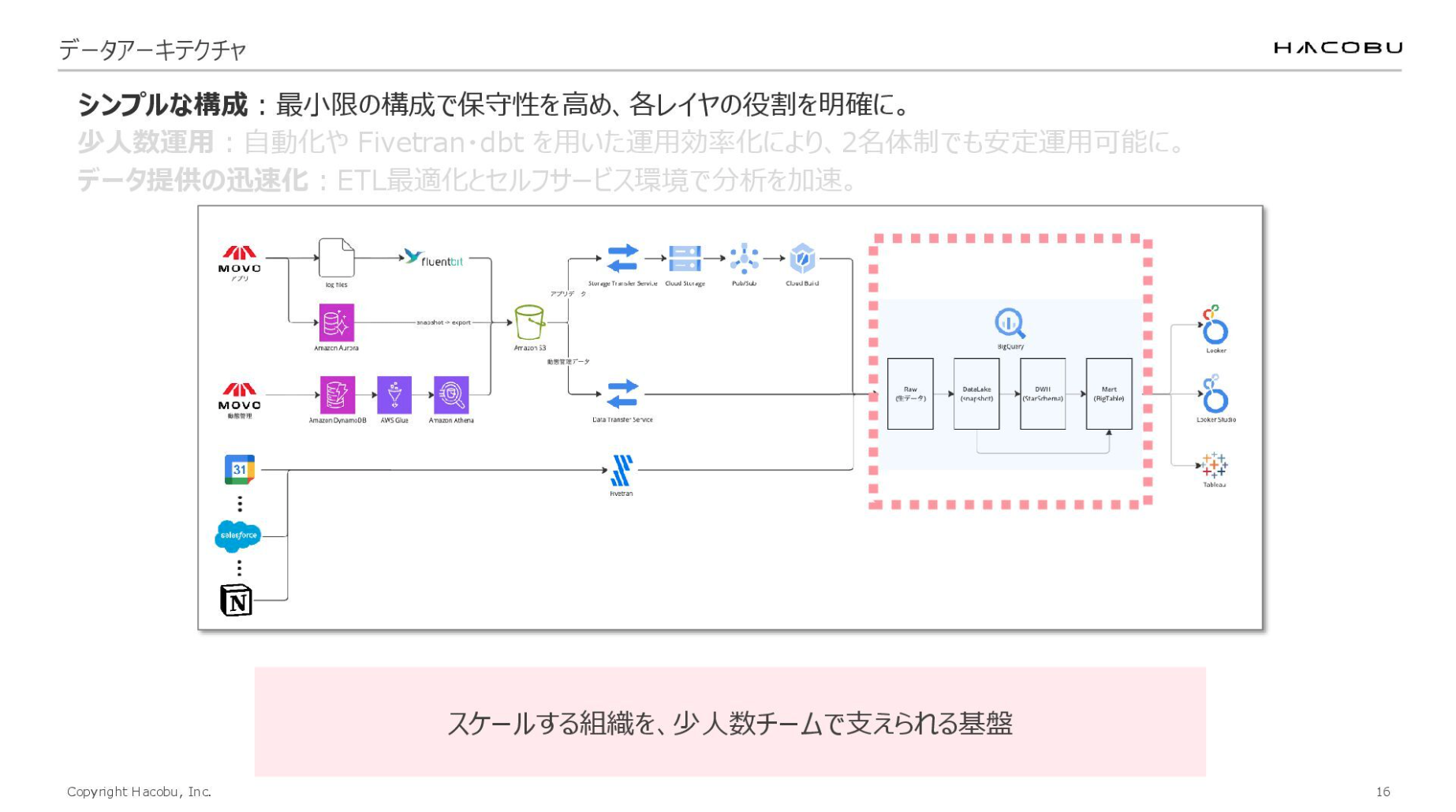
1つ目の「シンプルな構成」で大切なのは、複雑化・肥大化するリネージの認知負荷を下げることです。データチームはとにかく時間がありません。様々なタスクに対応するためには、いかに認知負荷を下げるかが重要となります。
具体的にお話しすると、データ利活用が進むと、データ基盤は複雑になっていきます。例えば、個別の分析依頼に対し、その都度データモデルを用意するといった対応を続けると、複数のモデルが乱立します。
すると、後から「ロジックの詳細確認」や「項目の追加」「仕様変更」といった問い合わせが急増してしまう。その際、調査の対象はBI上のテーブルだけでなく、背後にある複雑なリネージやラップされたロジックを遡って確認する羽目になります。
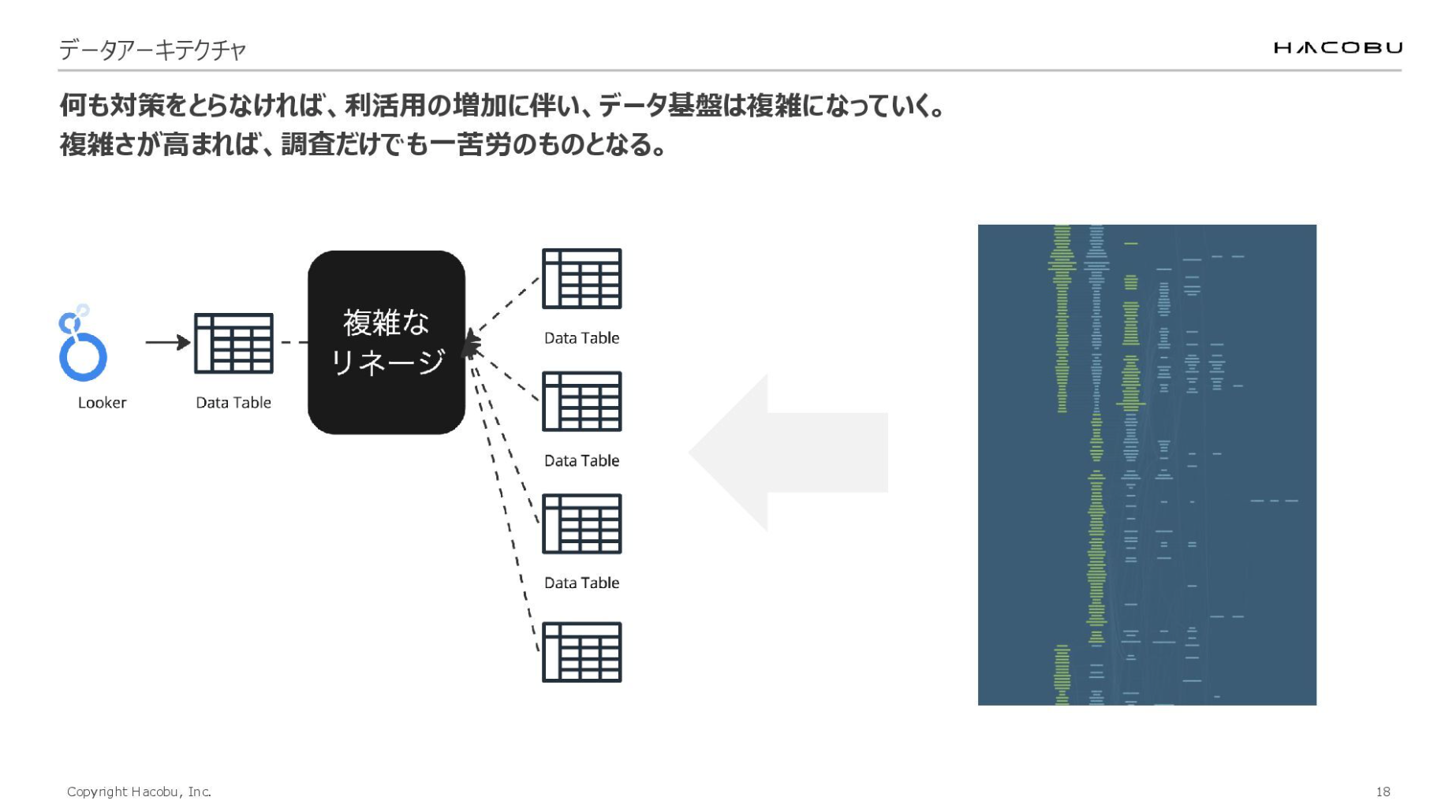
実例として、dbtのカタログを画像の右側に貼り付けました。これを見ても、何もわかりませんよね。データ基盤の調査には、とても時間がかかります。そのため、なるべくシンプルな構成にして、認知負荷を下げる取り組みが必要となるわけです。
シンプルな構成に必要なのは、モデリングです。当たり前のことになりますが、レイヤーごとの責務を明確にして、それを遵守して運用する。作る時だけではなく、運用する時もちゃんと遵守し続けることがシンプルさを保つために重要だと思います。
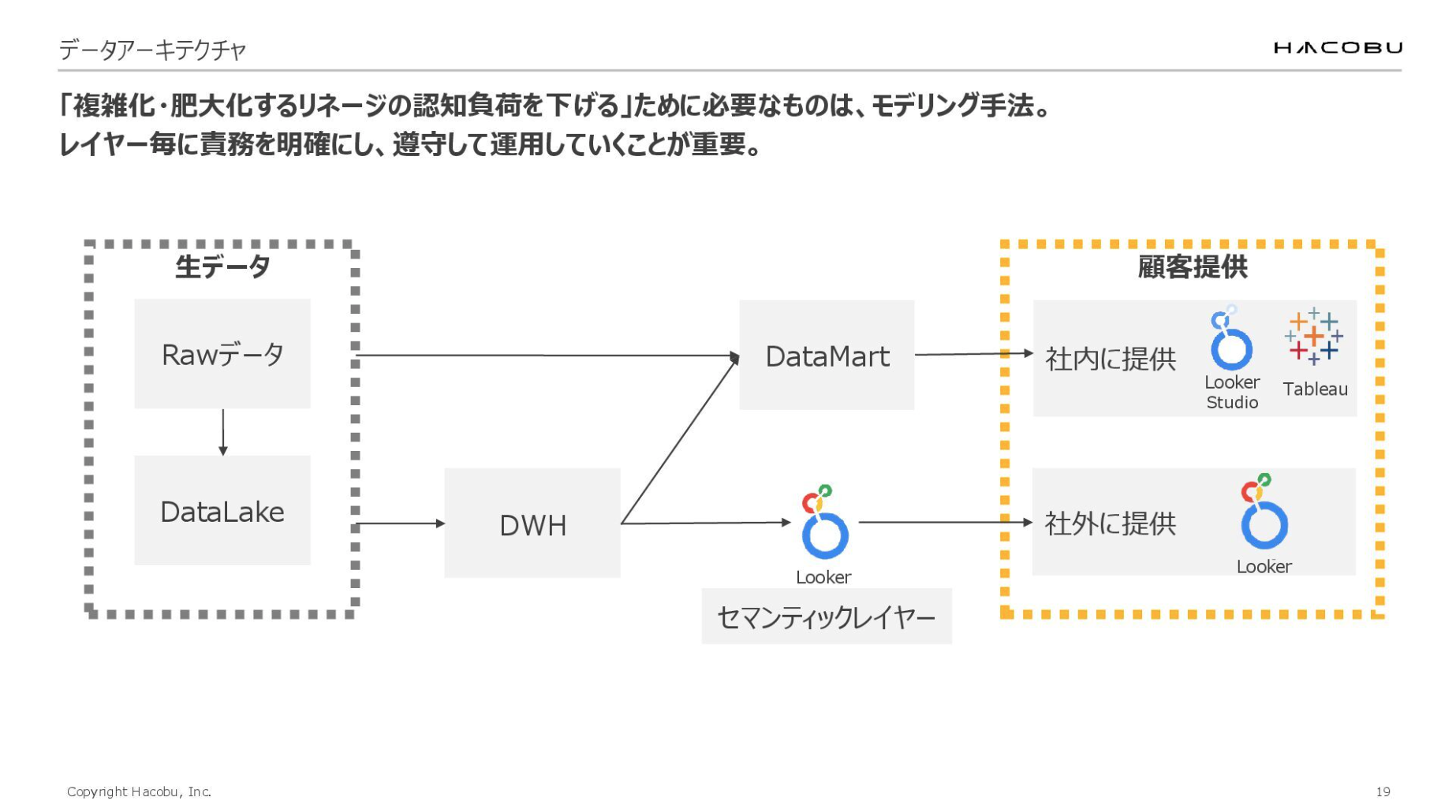
これは簡単な概念図ですが、データの流れをレイヤー別に構成しています。まず生データを集約・蓄積し、データウェアハウス(以下、DWH)を通したり、分析用途へ特化されたデータマートを切り出したりしています。また、ユーザーが扱いやすいように定義を共通化したセマンティックレイヤーも設けるなど、用途や目的に合わせた最適な階層で管理・提供しています。
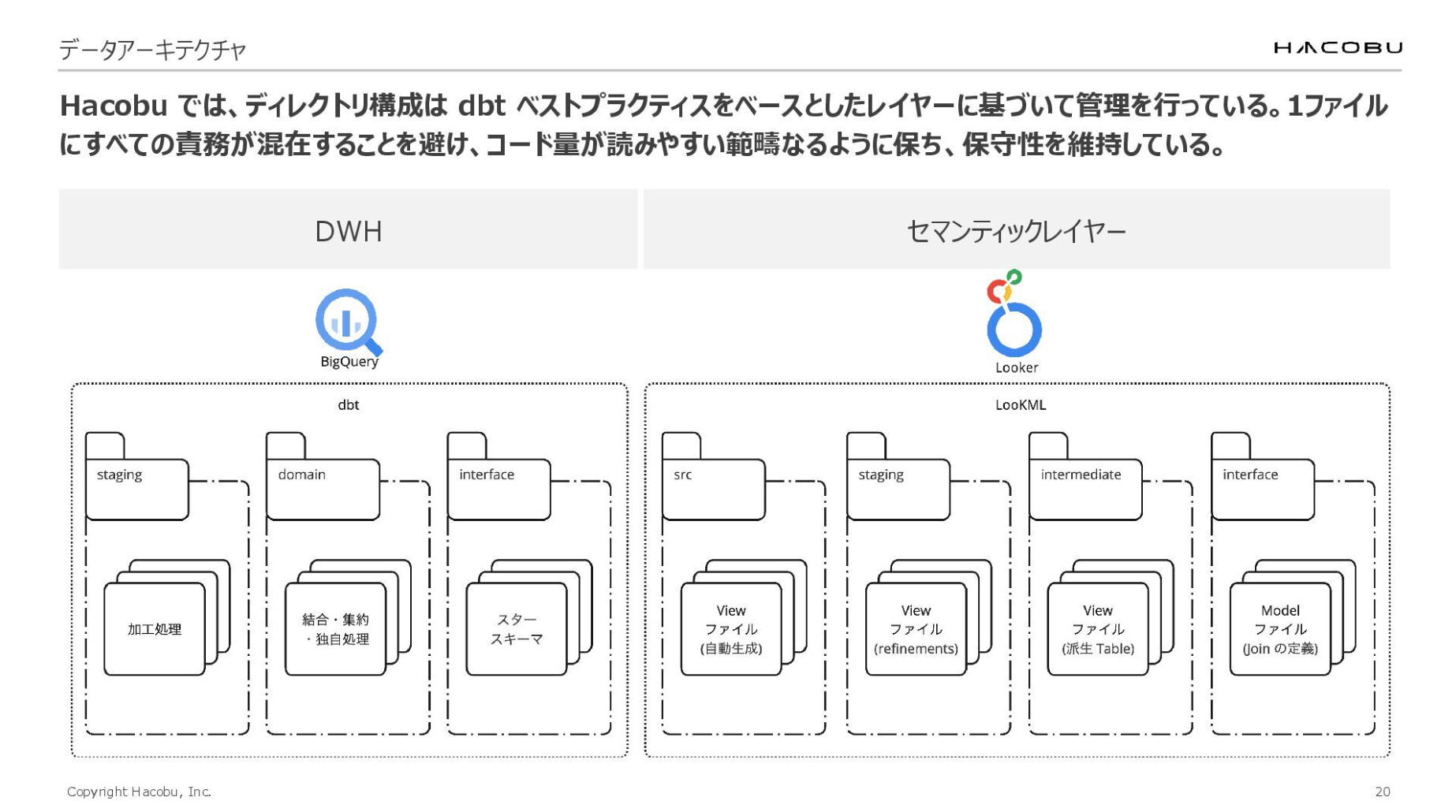
もう少し詳しく説明します。
まずDWHはディメンショナルモデリング(スタースキーマ)を採用し、dbtのベストプラクティスに準拠したレイヤー構成で構築しています。一部、独自の名称に変更している箇所はありますが「Staging / Intermediate / Mart」という役割の定義はそのまま継承しています。
セマンティックレイヤーはLookerのLookMLで構成しており、こちらの構造にもdbtのベストプラクティスを取り入れています。
このように、各レイヤーの境界と責務を厳格に定義・運用することで、コードの可読性が高まり、「どこで何が行われているか」が直感的に把握できるようになります。結果として、変化に強く高い保守性を維持した基盤を実現しています。
自動化・運用効率化で目指す「少人数運用」
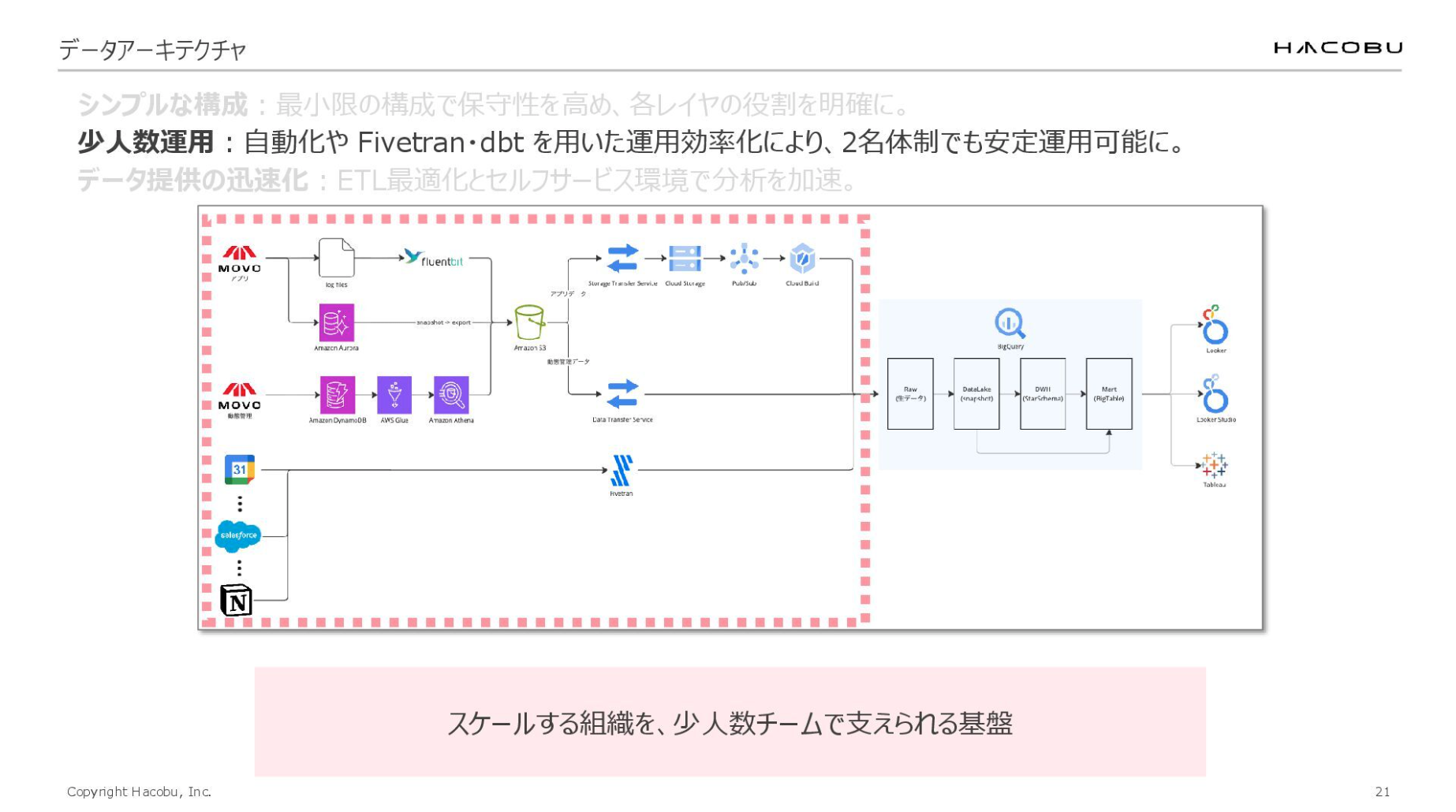
「少人数運用」については、エンジニアが対応する際の工数を如何に削減できるかどうかが重要です。先ほどもお話ししたように、データチームには時間がありません。人数に関係なく、どのチームも時間はないと思います。
先ほどは、保守性や実際に利用するためのモデルに関するお話(システムを”車”に例えた場合で言うところの、”車”自体の話)をしました。今度は、“ガソリン”に関するお話しです。
データの利活用が進むほど、「〇〇のデータも取り込みたい」「この活動データと掛け合わせたい」といった要望は自然と増えていきます。こうしたリクエストに対し、データチームがいかに手間をかけず、スピーディに対応できる環境を整えておくか。そこが、活用の勢いを加速させる重要なポイントです。
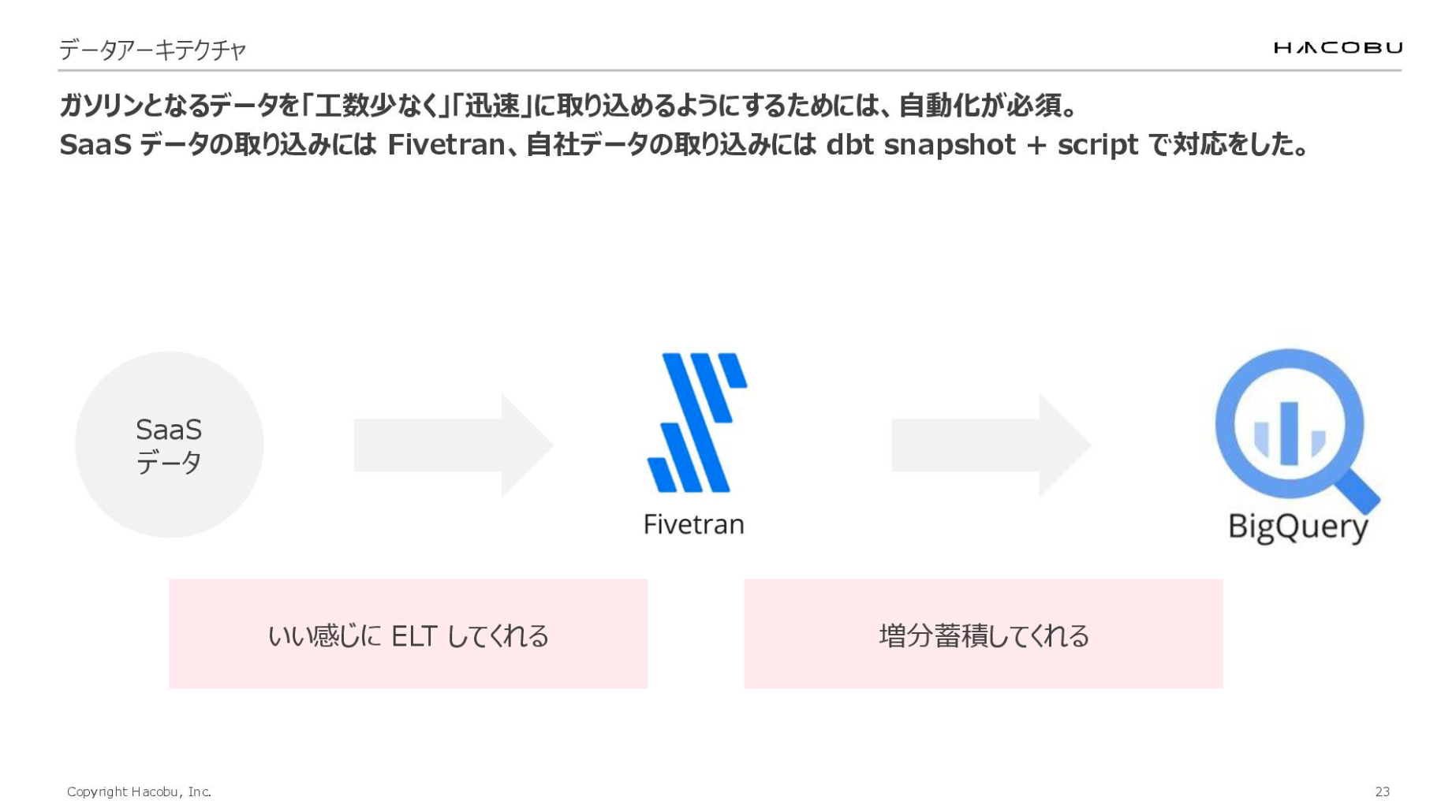
弊社ではSaaSデータと自社データで取り込みの仕方を少し変えており、前者ではFivetranを活用しています。
API経由のデータ取得は、コネクタの開発や各SaaS特有のデータ構造の把握にコストがかかりますが、Fivetranはこれらの工程をよしなに引き受けてくれます。BigQueryへの増分更新まで自動化されているため、自分たちの手間をかけることなく外部データを取り込めるようになっています。
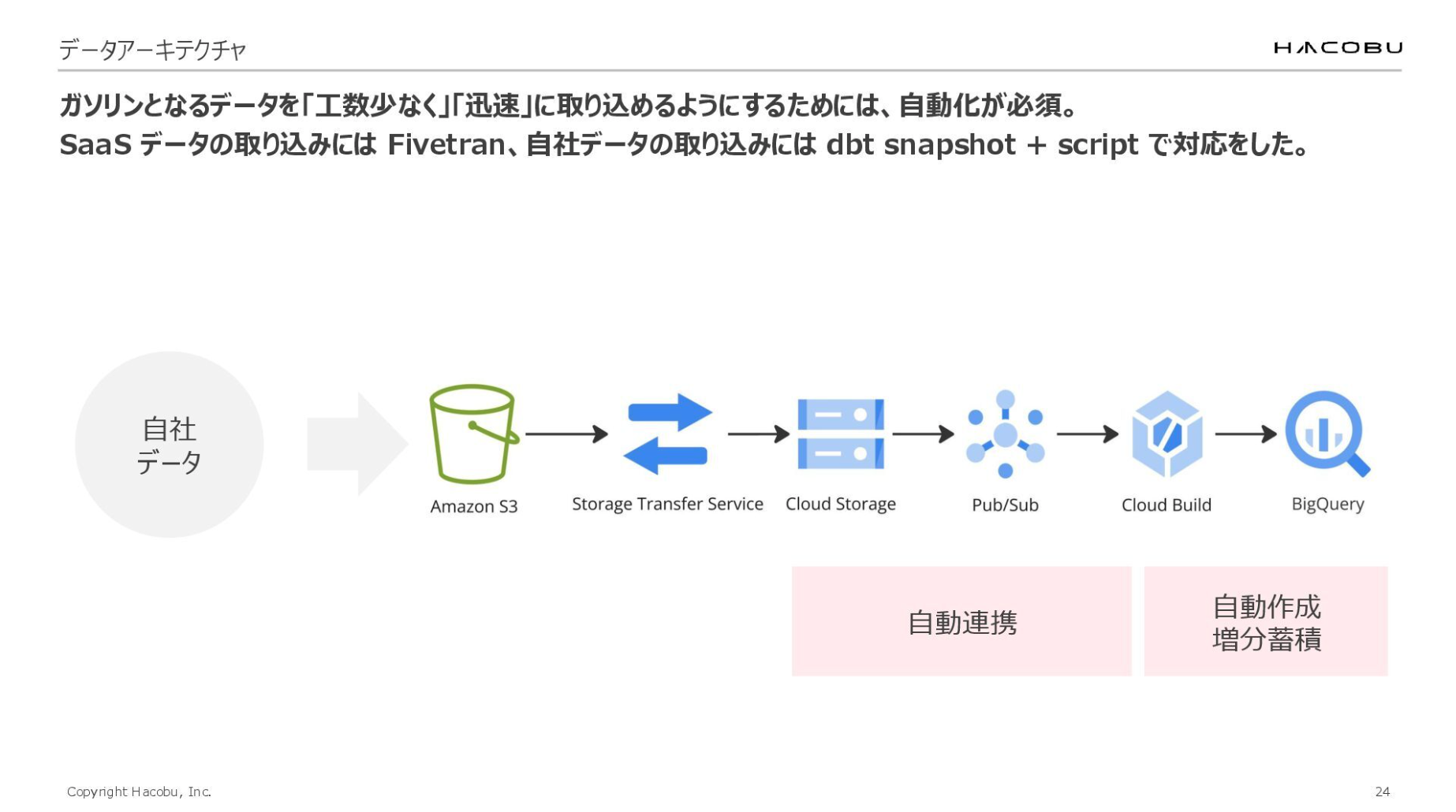
自社データについては、AWS上で運用しているため、S3を経由してGoogle Cloud(BigQuery)へ転送しています。現在はStorage Transfer Serviceを活用していますが、単純なバッチ処理では非同期連携ゆえのタイミングのズレや、それに伴う失敗のリスクがありました。
そこで、イベントソーシングによる自動連携で、データの到着に合わせてパイプラインが自動起動する仕組みを構築しています。また、取り込み工程ではCloud Build上でdbtを実行しており、テーブルの自動作成や増分蓄積にも対応させることで、運用の安定化を図っています。
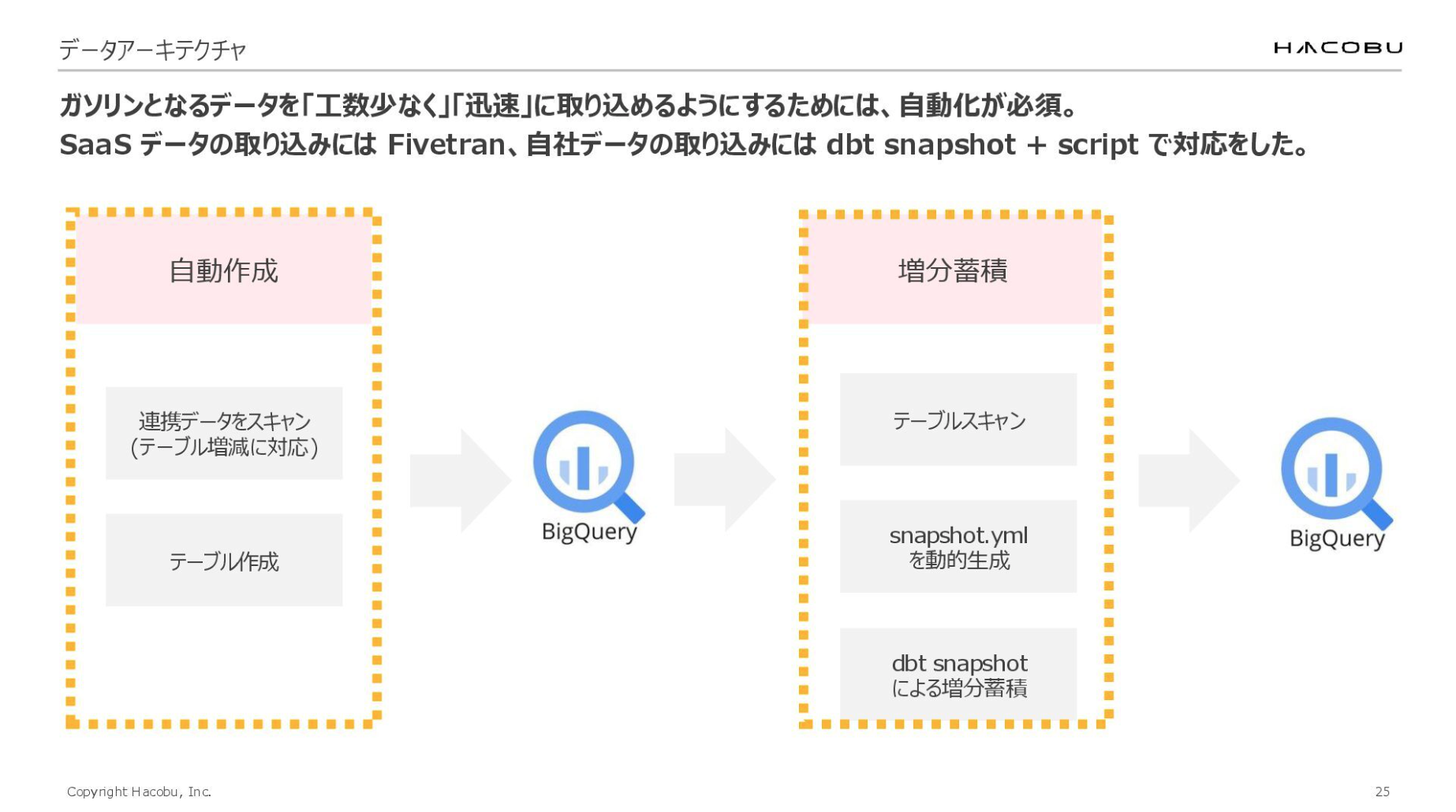
もう少し詳しくお話しすると、まずStorage Transfer ServiceでGCSに連携されたデータをスキャンし、BigQuery上にテーブルを自動生成する仕組みを構築しています。これにより、ソース側のテーブル増減にも柔軟に対応可能です。
こうして取り込んだローデータに対し、dbt snapshotを用いて履歴データの保持を自動化しています。ポイントは、スナップショット用のYAML定義自体もスクリプトで自動生成している点です。新しいデータが増えた際も、動的にスナップショットを回せる運用を実現しています。
このように、自社データは「dbt snapshot + スクリプト」で対応し、外部データは「Fivetran」で対応すると使い分けることで、新規データの取り込み依頼に対しても、最小限の工数でスピーディに応えられる体制を整えています。
横展開可能がもたらす「データ提供の迅速化」
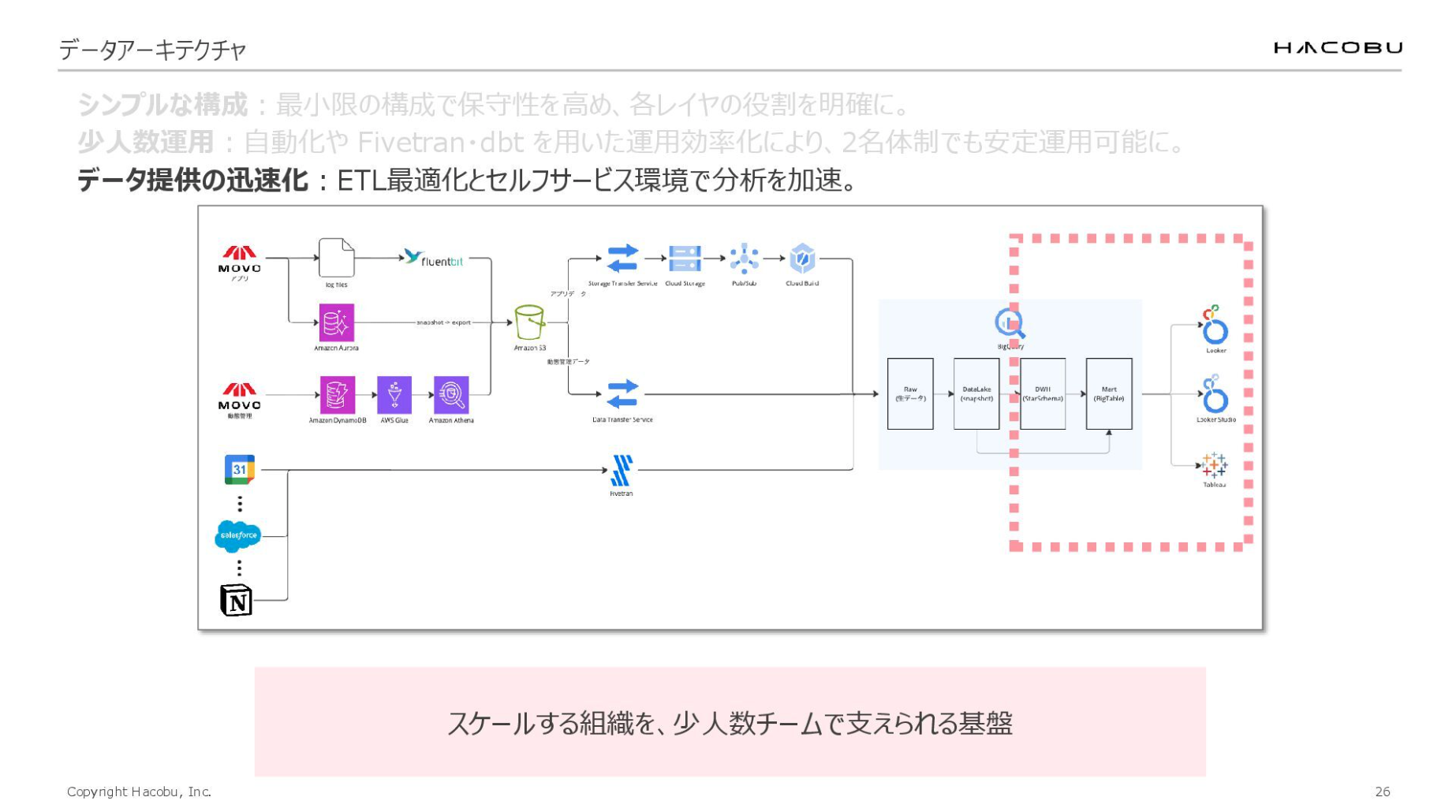
最後の「データ提供の迅速化」についてもお話しします。繰り返しになりますが、データチームには時間がありません。
そのためデータを利活用する際は、できるだけ「横展開可能」にしておく必要があります。
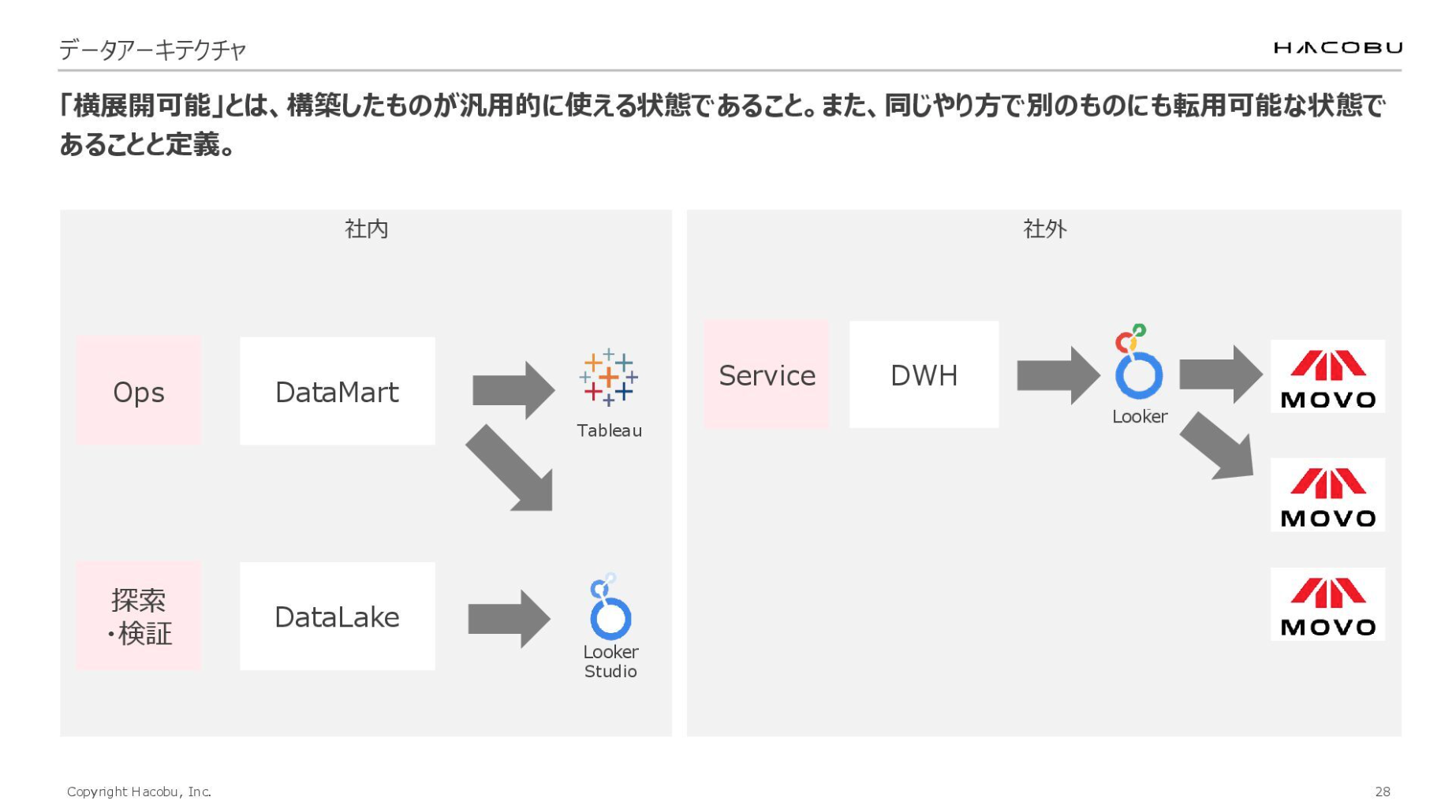
「横展開可能」とは、一度作ったものを同じやり方で別のものにも転用できる状態です。
例えば、社内向けには、用途に応じて2つの形態をとっています。定型的なオペレーション業務には、データマートからTableauやLooker Studioで可視化したダッシュボードを提供。業務フローが固まっていない場合は、直接データにアクセスして検索できる状態を担保しています。
社外向けには、データからセマンティックレイヤー(Looker)を経由して各プロダクトへ提供する仕組みにしています。
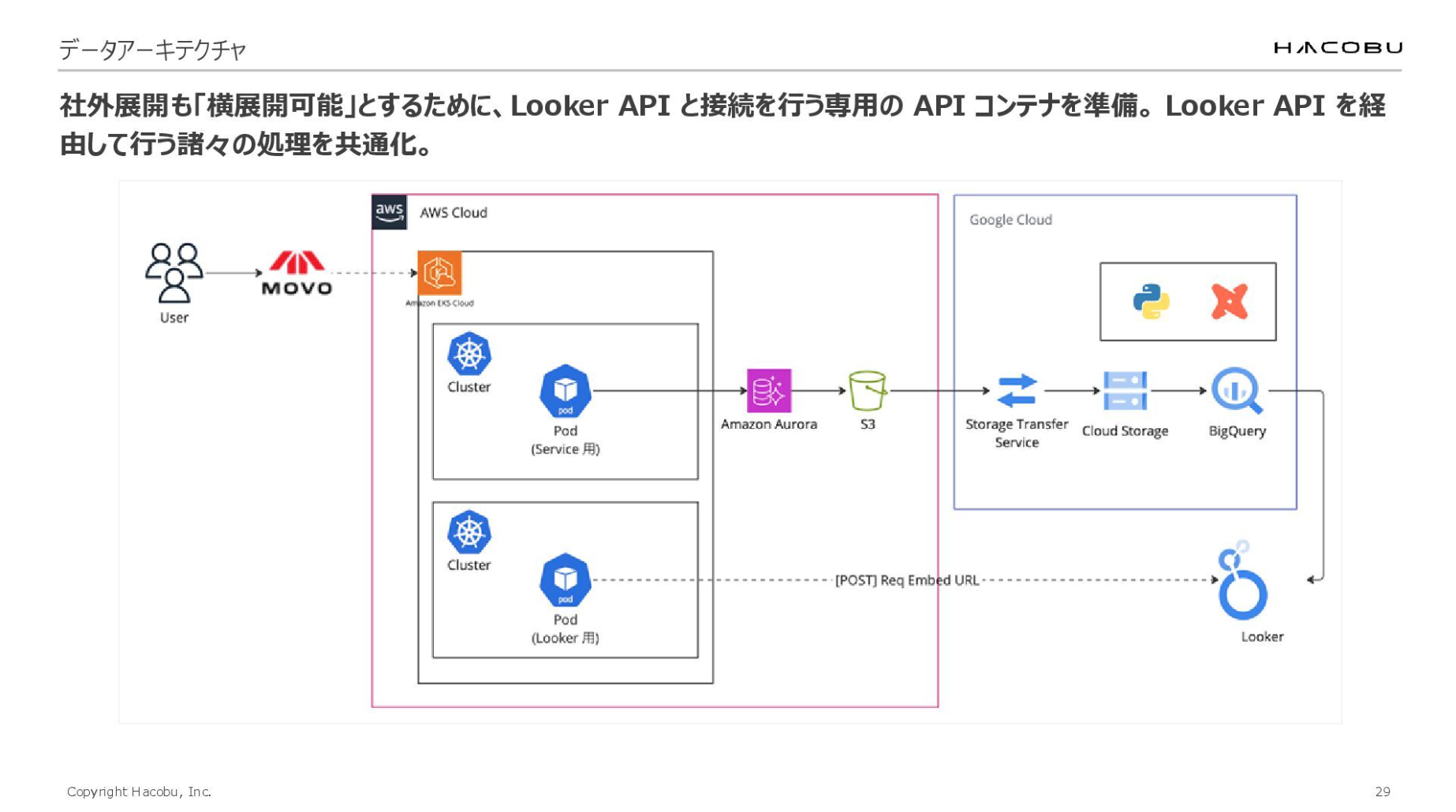
社外展開を横展開可能とするための仕組みについてもお話しします。
社外へ提供をする際は各「MOVO」上に、BIのダッシュボードを埋め込んでいます。ここでLooker APIを活用していますが、プロダクト間での横展開を容易にするため、接続ロジックをラップした共通コンテナを用意しました。このコンテナを各プロダクト側で展開するだけで、同じ機能を提供できる仕組みを構築しています。
少人数かつ時間がなくても運用できる基盤を構築
データアーキテクチャについてまとめます。Hacobuのデータアーキテクチャでは「シンプルな構成」「少人数運用」「データ提供の迅速化」というポイントをおさえることで、時間がない中でもなんとか運用できる基盤を構築しています。

ユーザーに「使ってもらえる」ようにするための分析レベル別アプローチ
高橋:ここからは、私が担当いたします。データアーキテクチャでは、データ提供の仕組みを中心にお話ししてきました。しかし、システムはユーザーに実際に使っていただいて、そこから価値が生まれてこそ、真価が発揮されます。ここからは、ユーザーの皆様に使ってもらえるようにするための具体的な取り組みをご紹介いたします。
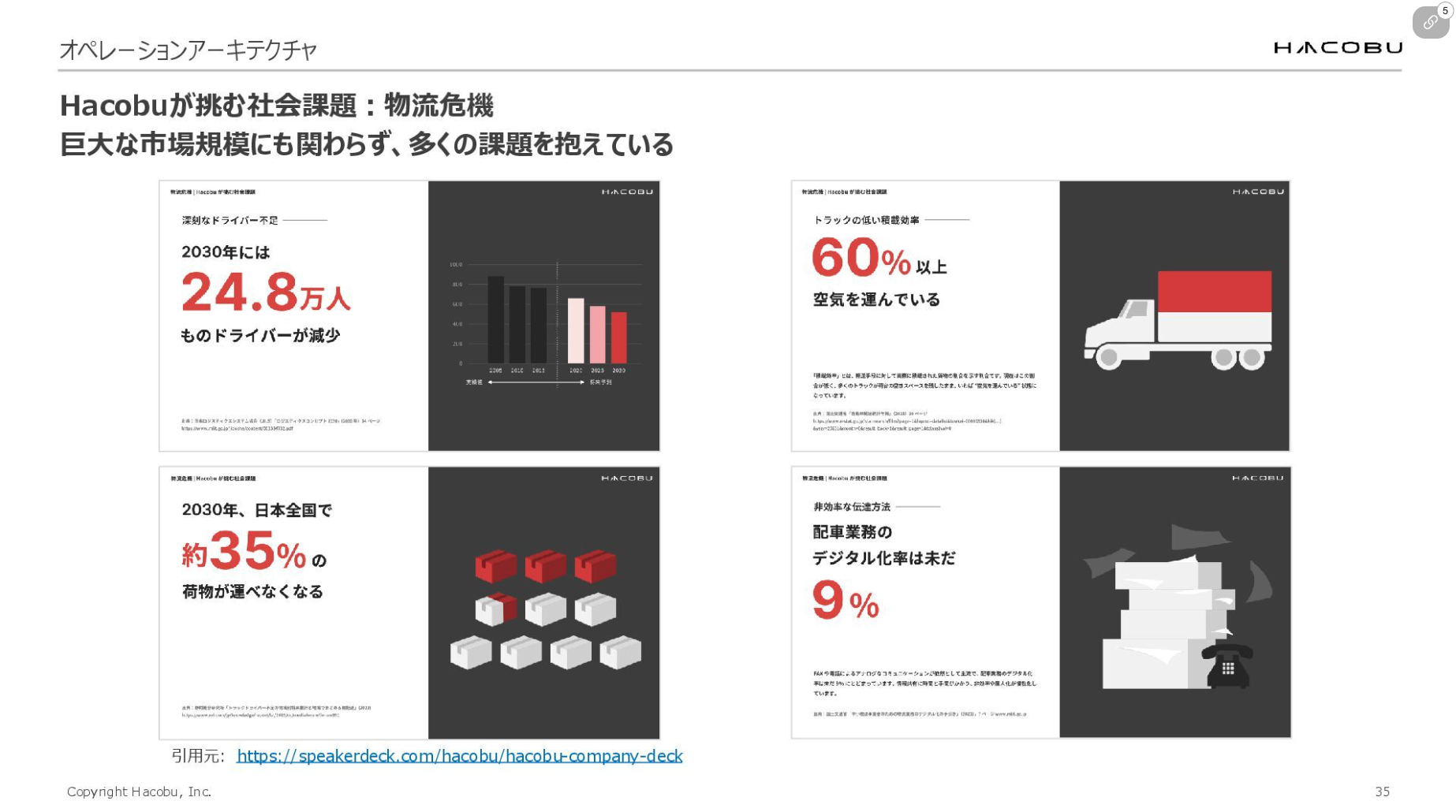
最初に、弊社が扱うデータの背景となるステークホルダーについて整理します。 私たちが解決を目指す「物流危機」は、国内GDPの10%ほどを占める巨大市場にもかかわらず、多くの課題を抱えています。Hacobuは、そういった課題の解決を目指して物流DXツールやコンサルティングサービスを提供してきました。
その中で見えてきたのは、物流ドメイン特有の「データの複雑性」でした。
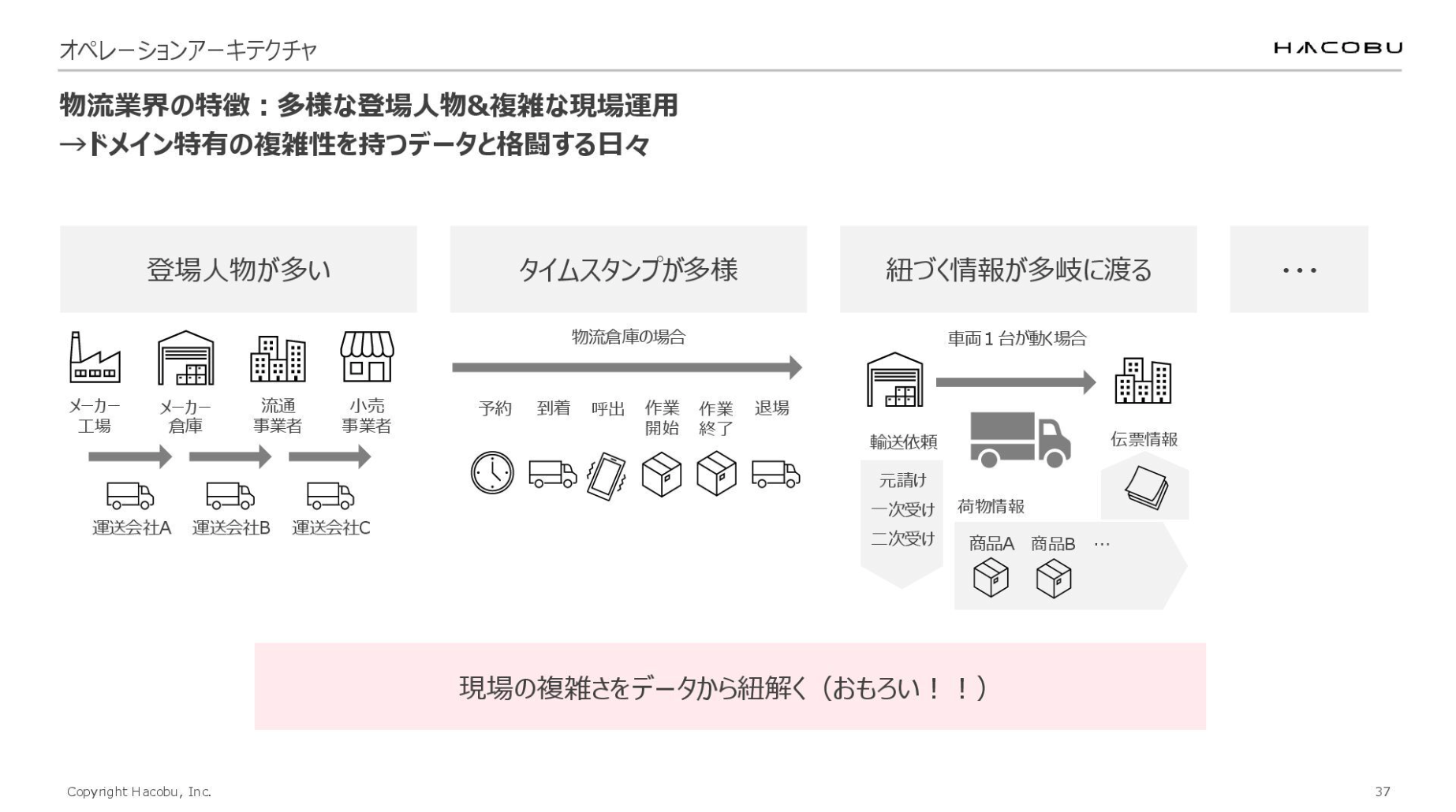
多数の登場人物、無数に存在するタイムスタンプ、そして車両一台に対し複雑に絡み合う属性情報など。 このように非常に難易度の高いデータを、いかにしてユーザーが活用できる状態へ持っていくのか。「使ってもらえるデータ活用」について、お話していきます。
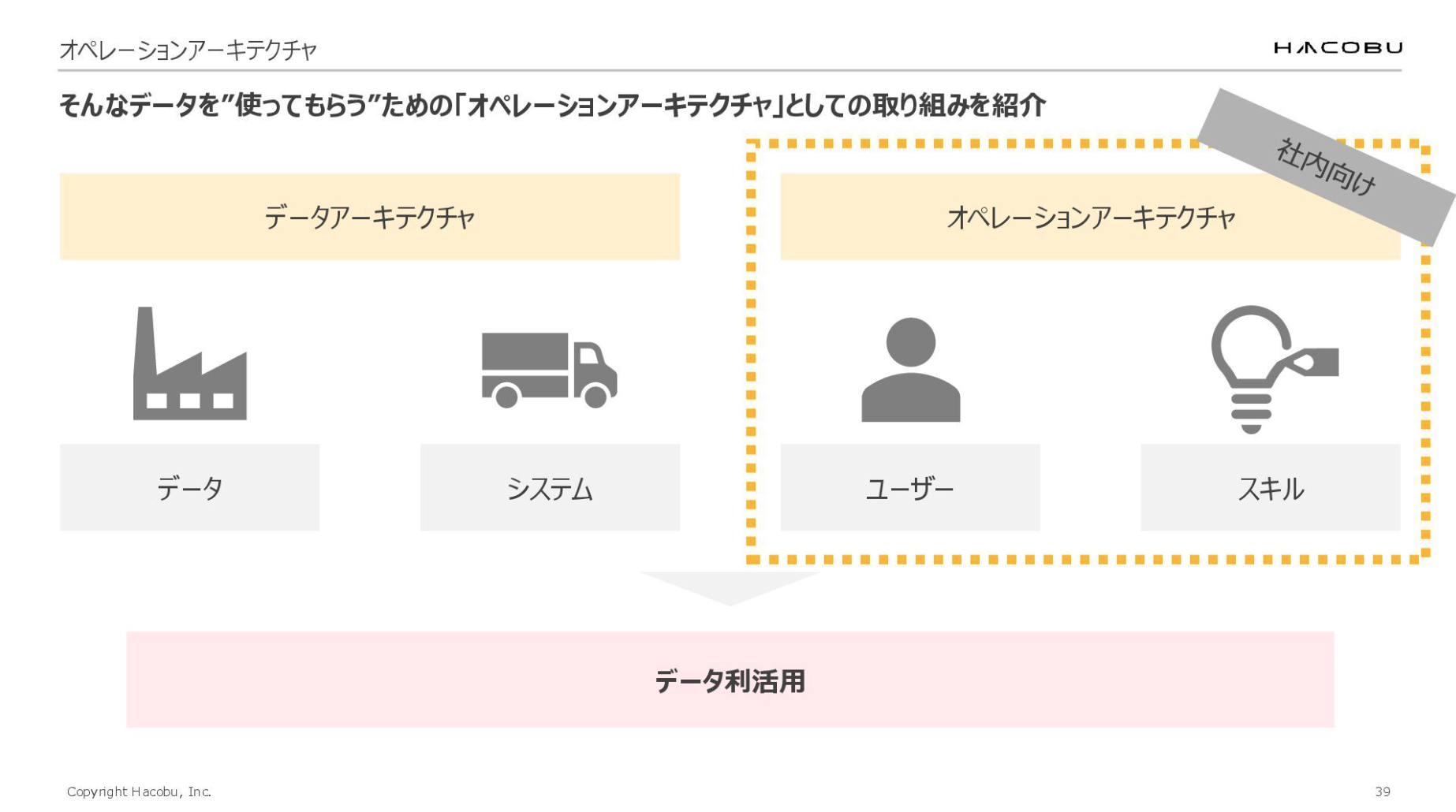
今回は「ユーザー」と「スキル」の2つの視点に焦点を当てます。現在は社外にまで利用が広がりつつありますが、本日は社内に向けて取り組んだ内容に絞ってお話しさせていただきます。

まず、ユーザーに作ったデータ基盤を使ってもらうために必要となるのは「データを使った意思決定がしたい」「原因をデータから特定したい」「成果をデータから見える化したい」といったモチベーションだと考えています。Hacobuには「データドリブン・ロジスティクス」という考えのもと、データを使おうという企業文化が存在していたものの、実際にはデータ利活用に対する心理的な壁がありました。
スキルについて必要だったのは、データ分析リテラシーのある人材です。どのデータを使うべきかを知っている。そして、それをどのように可視化すればデータから示唆を得ることができるのかを把握している。データ基盤を使いこなすためには、そこまで理解しておかなくてはいけません。ここでの課題は「やりたいけど、できない」という点にありました。当初は、社内の依頼に全て私が応えていたのですが、それだと当然ながらスケールしません。私自身がボトルネックとなっており、データ分析リテラシーのある人材不足が課題となっていました。
「データ分析に対する抵抗感」「データ分析リテラシーのある人材不足」という課題に対して、私たちはどのようなアクションを起こしたのか。結論としては、分析レベルを「未経験」「初心者~中級者」「上級者」という3つのレイヤーに分けて、各レベルに応じた3つのアプローチをとりました。
「未経験」向けのライトなオンライン講座
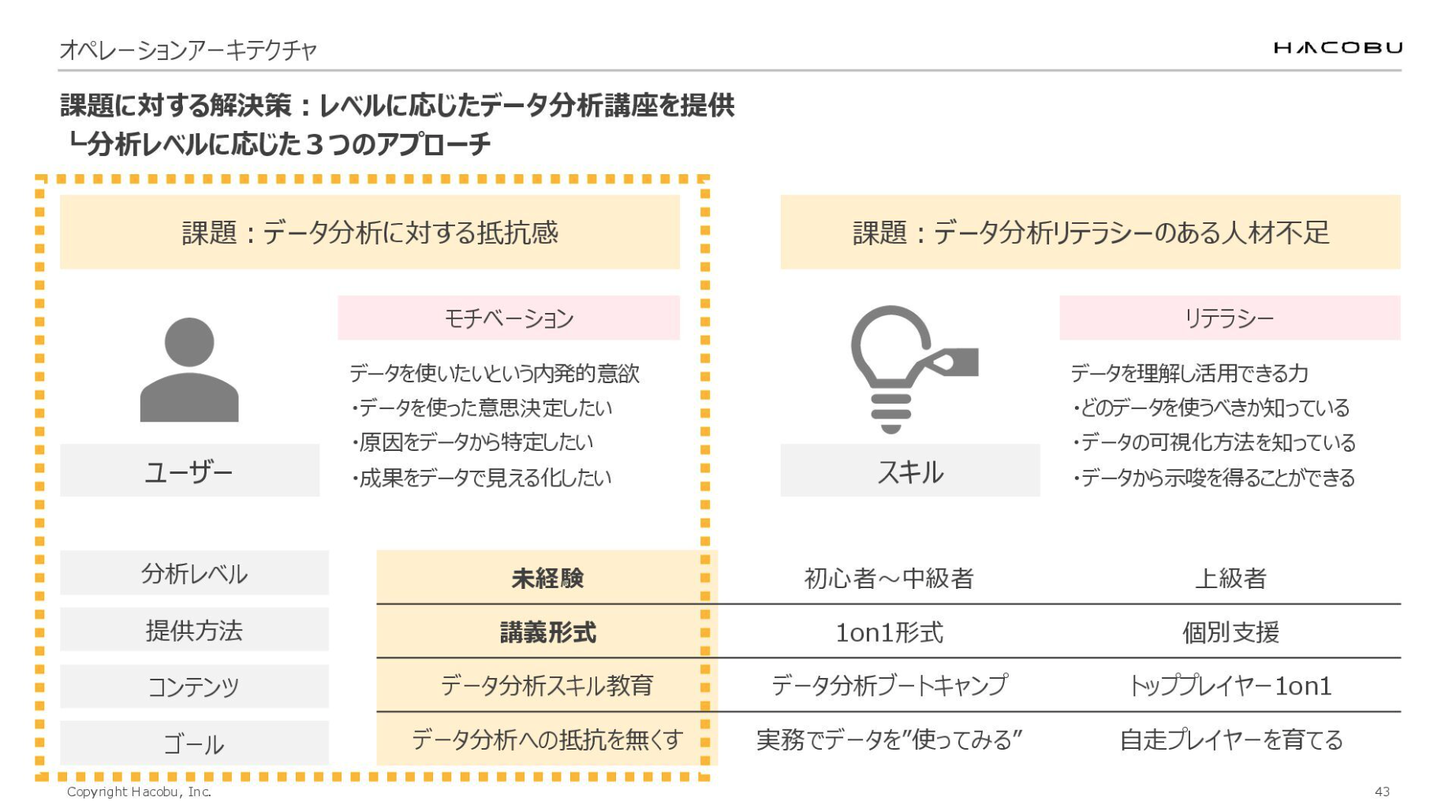
まず、ユーザーの「データ分析への抵抗感」を解消するため、講義形式でのアプローチを試みました。具体的には、データ分析の基本的な考え方、Excel関数、Looker Studioの使用法などをテーマに、30分程度の短時間で気軽に参加できるオンライン講座を実施し、その録画を自由に視聴できるようにしました。

この講座には、当時の社員の約半数が参加してくれて「データ分析についてよく分かっていなかったが、講座に参加したことで自分にもできそうだと思えた」という感想をもらうことができました。また、講座に参加した社員から、データの可視化に関する相談が届くようになりました。
「初心者~中級者」向けのデータ分析ブートキャンプ
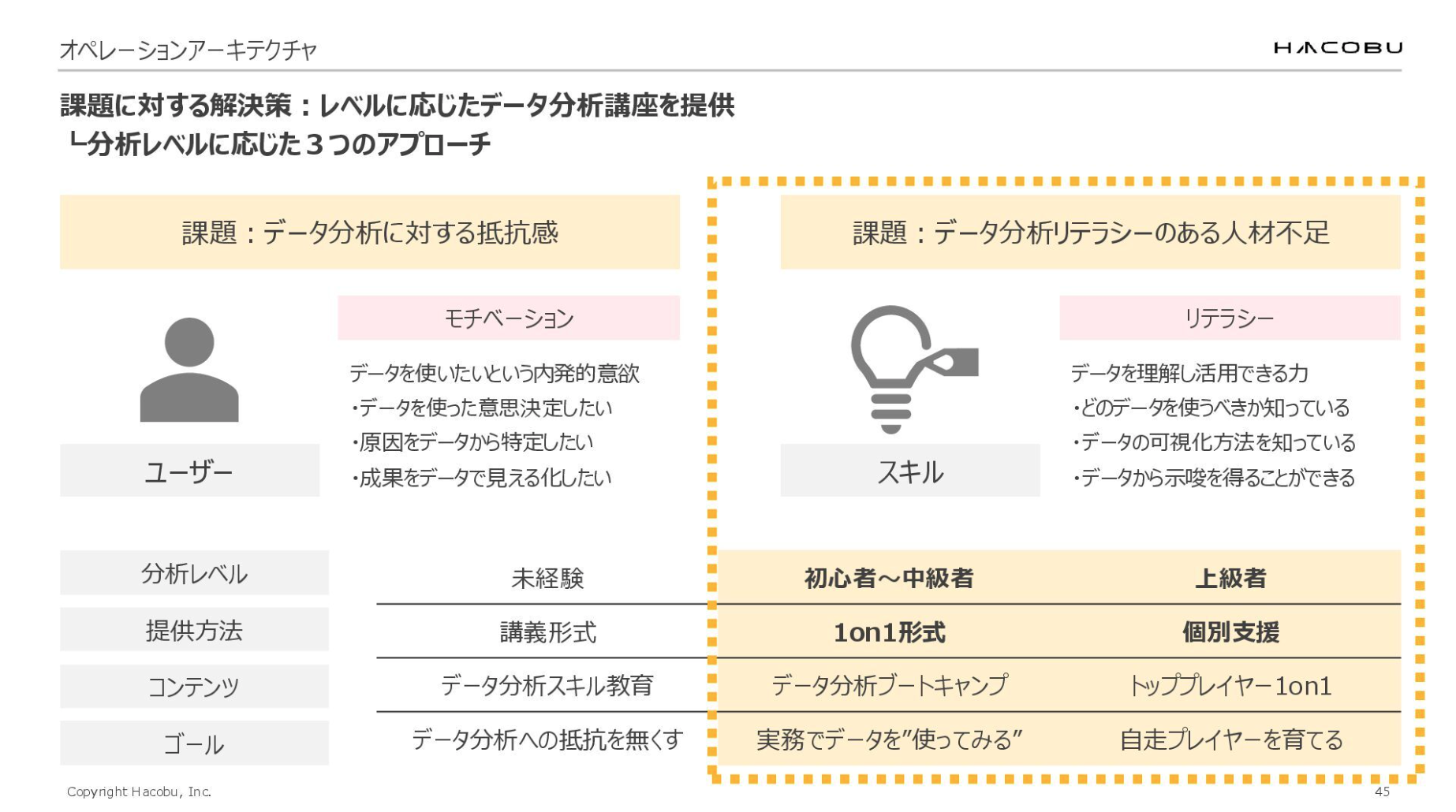
スキルの課題としてあがっていた「データ分析リテラシーのある人材不足」については、初心者~中級者、上級者に分けてアプローチを実施しております。

初心者~中級者向けに行ったのは「データ分析ブートキャンプ」です。希望者を5名ほど募り、1ヶ月から1ヶ月半かけて週1ペースで1on1セッションを実施。ブートキャンプ期間中は、各自が持ち込んだ分析テーマに取り組みました。
「データ分析ができれば何でもいい」という方針で参加のハードルを下げ、マーケティング部門の数値分析、総務部門の会議室利用状況分析、人事部門の採用歩留まり分析など、様々な部門からの要望に対応しました。
結果として、計5回延べ25名が参加し、参加者はLooker Studioでダッシュボードを作成できるようになりました。また、簡単な可視化は自分たちで行うなど自走できる人が増加し、社内教育を推進できる人も誕生しました。作成したダッシュボードは全社の公式データとして実業務でも活用されています。
データ分析リテラシーのある人材不足という課題に対し、最初の入り口として「データを使ってみる」人を増やすことに成功した取り組みだと言えると思います。
「上級者」向けの個別支援

上級者向けには、個別支援の形でアプローチしています。具体的には社内で約3名の上級者を対象とし、非エンジニア出身でありながら、AI活用によりSQLの記述やダッシュボード作成が可能になった人材に焦点を当てました。
彼らとは基本的に週次の1on1でコミュニケーションを取り「その目的であれば、このデータを使った方がいい」「可視化はこうする方がいいのでは」「スポット分析なら、ダッシュボードである必要はないのでは」といった具体的なアドバイスをして、3名が自走できるようにサポートをしました。
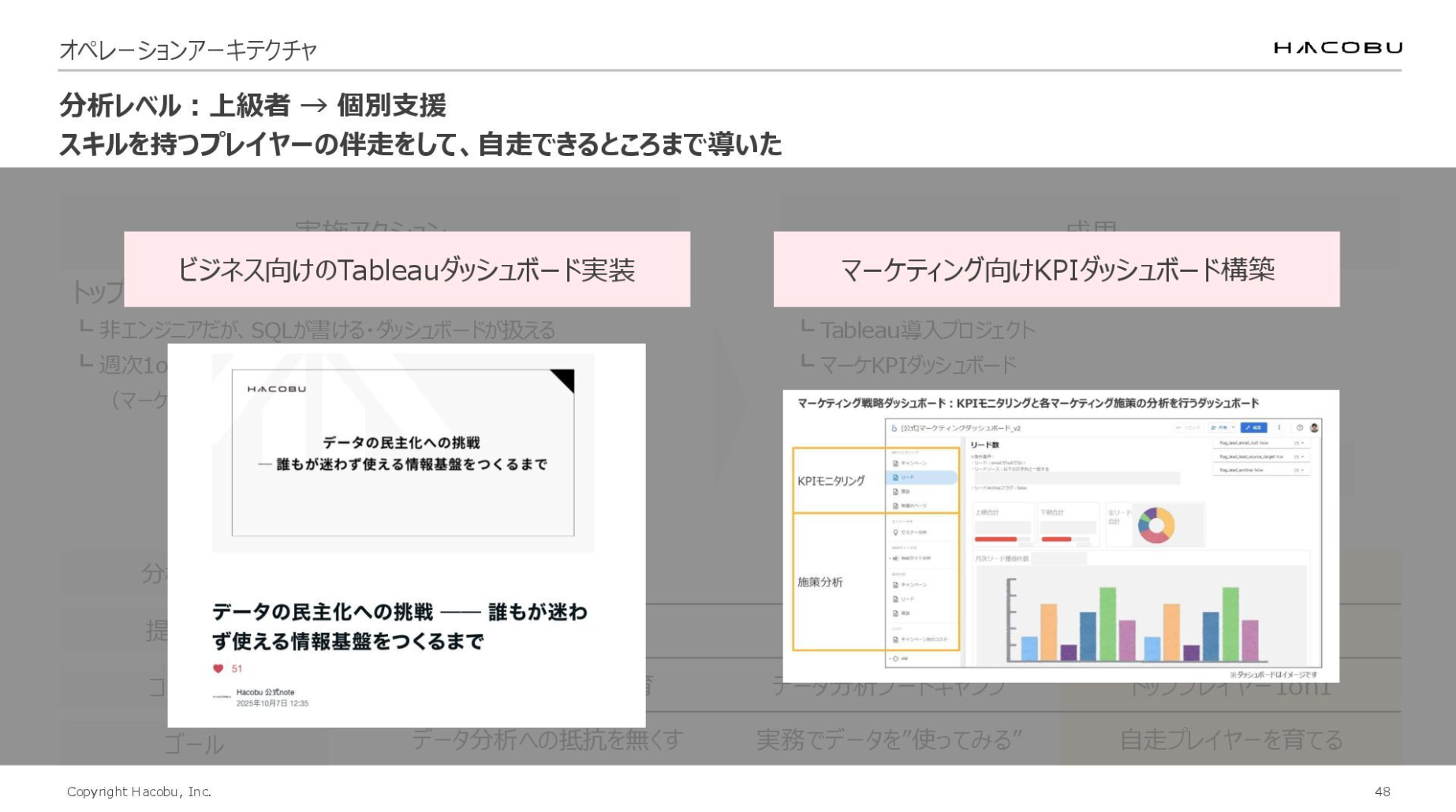
結果として、自走プレイヤーが誕生しました。こちらに載せているビジネス向けのTableauダッシュボードやマーケティング向けKPIのダッシュボードなどは、その実装のほとんどを1on1でレクチャーしたメンバーが担当しました。
レベル別のアプローチでデータ活用を推進する体制を実現

「データ分析に対する抵抗感」「データ分析リテラシーのある人材不足」といった2つの課題は、レベルに応じたデータ分析講座を行うことで解決ができたと思います。
過去には私1人で対応し、私自身がボトルネックとなっていましたが、取り組みを通して会社全体でデータ活用を進めていく体制を作ることができました。

システムと組織の「両輪」で、AIと共にスケールするデータ基盤の実現を目指す
高橋:まとめに入ります。本日は「社内外から"使ってもらえる"データ基盤を支えるアーキテクチャの秘訣」と題して、前半では使ってもらえるようにするためのアーキテクチャ、後半では基盤を使ってもらって価値に繋げていくための取り組みについてお話しました。
最初に冒頭でもお伝えした通り、使ってもらえるデータ基盤の例として、何か1つでも現場に持ち帰ってもらえるヒントになっていれば嬉しい限りです。
最後に、私たちがこれから挑戦してみたいこととしては「人に依存しない形で、AIと共にスケールさせていくデータ基盤」を実現していきたいと考えています。
ご清聴ありがとうございました。

アーカイブ動画・発表資料
イベント本編は、アーカイブ動画を公開しています。また、当日の発表資料も掲載しています。あわせてご覧ください。
▼動画・資料はこちら
アーキテクチャConference 2025
※動画の視聴にはFindyへのログインが必要です。





